Cet article peut être librement diffusé et son contenu réutilisé pour une utilisation non commerciale (contacter l’auteur pour une utilisation commerciale) suivant la licence CC-by-nc-sa
Dans le programme de mathématiques de première générale (spécialité Mathematiques) on trouve parmi la liste des compétences mathématiques travaillées :
– calculer, appliquer des techniques et mettre en œuvre des algorithmes ;
Ainsi, il y a dans ce programme des indications au sujet de ces algorithmes que l’on peut mettre en œuvre, nous allons ici les illustrer.

Algèbre
Liste des premiers termes d’une suite : suite de Syracuse, suite de Fibonacci
La suite de Fibonacci est une suite d’entiers dans laquelle chaque terme est la somme des deux termes qui le précèdent. Elle commence généralement par les termes 0 et 1 (parfois 1 et 1) et ses premiers termes sont : 0, 1, 1, 2, 3, 5, 8, 13, 21, etc.
Une première version du calcul de ces termes peut consister à utiliser deux variables a et b, initiées à 1, et à chaque boucle on met le contenu de b dans a et a+b dans b, soit :
def fibonacci1(n):
a=1
b=1
for n in range(n):
a,b=b,a+b
return aUtilisation :
>>> fibonacci1(20)
10946Une seconde version s’appuiera sur la récurrence double de la suite : $u_{n+1}=u_n + u_{n−1}$
def fibonacci2(n):
if (n==0) or (n==1):
return 1
else:
return fibonacci2(n-1)+fibonacci2(n-2)Comme fibonacci2(0)= fibonacci2(1)=1, le code ci-dessus peut calculer fibonacci2(2) et les suivants.
Utilisation :
>>> fibonacci2(20)
10946Nombre d’Or : Un problème numériquement intéressant (et c’était la motivation initiale de Fibonacci) est d’étudier le comportement du rapport entre deux termes successifs de la suite de Fibonacci, on pourra dans fibonacci1() renvoyer b/a et pour fibonacci2() créer une nouvelle fonction :
def rapport(n):
return fibonacci2(n+1)/fibonacci2(n)On conjecture alors que la suite de Fibonacci tend vers le nombre d’or : $\varphi =\frac {1+\sqrt {5}}{2}$.
La suite de Syracuse ou suite de Collatz est une suite d’entiers naturels définie de la manière suivante : on part d’un nombre entier naturel non nul ; s’il est pair, on le divise par 2 ; s’il est impair, on le multiplie par 3 et on ajoute 1. En répétant l’opération, on obtient une suite d’entiers positifs dont chacun ne dépend que de son prédécesseur.
Par exemple, à partir de 28, on construit la suite des nombres : 28, 14, 7, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1, 4, 2… C’est ce qu’on appelle la suite de Syracuse du nombre 14.
Une fois que le nombre 1 est atteint, la suite des valeurs (1,4,2,1,4,2…) se répète indéfiniment en un cycle de longueur 3, appelé cycle trivial.
Si l’on était parti d’un autre entier, en lui appliquant les mêmes règles, on aurait obtenu une suite de nombres différente. A priori, il serait possible que la suite de Syracuse n’atteigne jamais la valeur 1, pour une valeur de départ bien choisie, soit qu’elle aboutisse à un cycle différent du cycle trivial, soit qu’elle diverge vers l’infini. Or, on n’a jamais trouvé d’exemple de suite obtenue suivant les règles données qui n’aboutisse pas à 1.
Voici le calcul des termes de la suite pour n entier naturel non nul :
def syracuse(n):
suite=[]
u=n
while(u>1):
if u%2:
u=3*u+1
else:
u//=2
suite.append(u)
return suiteUtilisation :
>>> syracuse(65)
[196, 98, 49, 148, 74, 37, 112, 56, 28, 14, 7, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1]L’observation graphique de la suite pour N = 15 et pour N = 127 montre que la suite peut s’élever assez haut avant de retomber. Les graphiques sont chaotiques. De cette observation est né tout un vocabulaire imagé : on parlera du vol de la suite.
On définit alors :
– le temps de vol : c’est le plus petit indice n tel que $u_n = 1$. Il est de 17 pour la suite de Syracuse 15 et de 46 pour la suite de Syracuse 127 ;
– le temps de vol en altitude : c’est le plus petit indice n tel que $u_{n+1} ≤ u_0$. Il est de 10 pour la suite de Syracuse 15 et de 23 pour la suite de Syracuse 127 ;
– l’altitude maximale : c’est la valeur maximale de la suite. Elle est de 160 pour la suite de Syracuse 15 et de 4 372 pour la suite de Syracuse 127.
Le code suivant calcule ces différentes valeurs et graphe la suite en utilisant la librairie Matplotlib.
import matplotlib.pyplot as plt
suite = []
def syracuse(n):
u=n
suite.append(u)
while(u>1):
if u%2:
u=3*u+1
else:
u//=2
suite.append(u)
return suite
def graphique(n):
ax=plt.axes()
syracuse(n)
temps_vol_altitude=0
alt_max=max(suite)
len_suite=len(suite)
for i in range(1,len_suite-1):
if suite[i]>=suite[0]:
temps_vol_altitude+=1
else:
break
plt.plot(list(range(len_suite)),suite,'b.', linestyle='solid')
plt.grid()
plt.text(len_suite/3, alt_max, "Temps de vol : "+str(len_suite))
plt.text(len_suite/3, alt_max*0.95, "Altitude maximum : "+str(alt_max))
plt.text(len_suite/3, alt_max*0.9, "Temps de vol en altitude : "+str(temps_vol_altitude))
plt.title("Suite de Syracuse pour n ="+str(n))
ax = ax.set(xlabel='Temps de vol', ylabel='Altitude')
plt.show()Utilisation :
>>> graphique(15)Voici ce que l’on obtient :

- Syracuse pour n=15
Essayez avec 2019 ...
Analyse
Écrire la liste des coefficients directeurs des sécantes pour un pas donné.
Pour une fonction $f$ continue sur un intervalle $[a ; b]$, on coupe l’intervalle en $n$ morceaux et on obtient $(n+1)$ points de la courbe avec $A_0 (a ; f(a))$ et $A_n (b ; f(b))$, on calcule les coefficients directeurs des droites $(A_i A_{i+1})$ pour i allant de 0 à $n - 1$ :
def f(x):
return x**2-2*x+7
def coeffs_secantes(f,a,b,n):
liste_coeffs=[]
h=(b-a)/n
for i in range(n):
liste_coeffs.append(round((f(a+h*(i+1))-f(a+i*h))/h,2))
return liste_coeffsUtilisation :
>>> coeffs_secantes(f,-5,5,25)
[-11.6, -10.8, -10.0, -9.2, -8.4, -7.6, -6.8, -6.0, -5.2, -4.4, -3.6,
-2.8, -2.0, -1.2, -0.4, 0.4, 1.2, 2.0, 2.8, 3.6, 4.4, 5.2, 6.0, 6.8, 7.6]

- Courbe avec ses sécantes
Méthode de Newton, en se limitant à des cas favorables
| Soit $f$ une fonction dérivable sur un intervalle $I$. L’équation $f (x) = 0$ admet une racine unique $\alpha$ sur cet intervalle $I$. Soit $a \in I$ une valeur approchée de $\alpha$. On va utiliser l’approximation affine $g$ de $f$ au point $a$. On aura donc $g(x) = f (a) + (x − a)f ′(a)$ (tangente $T_a$). La droite $T_a$ coupe l’axe des abscisses en $b = a −\frac{f(a)}{f’(a)}$. Sous certaines conditions, le nombre $b$ peut représenter une meilleure approximation de $\alpha$ que $a$. La méthode de Newton consiste à itérer le processus en repartant de $b$ et ainsi de suite. On proposera deux solutions : – si l’on sait dériver la fonction $f$.
|
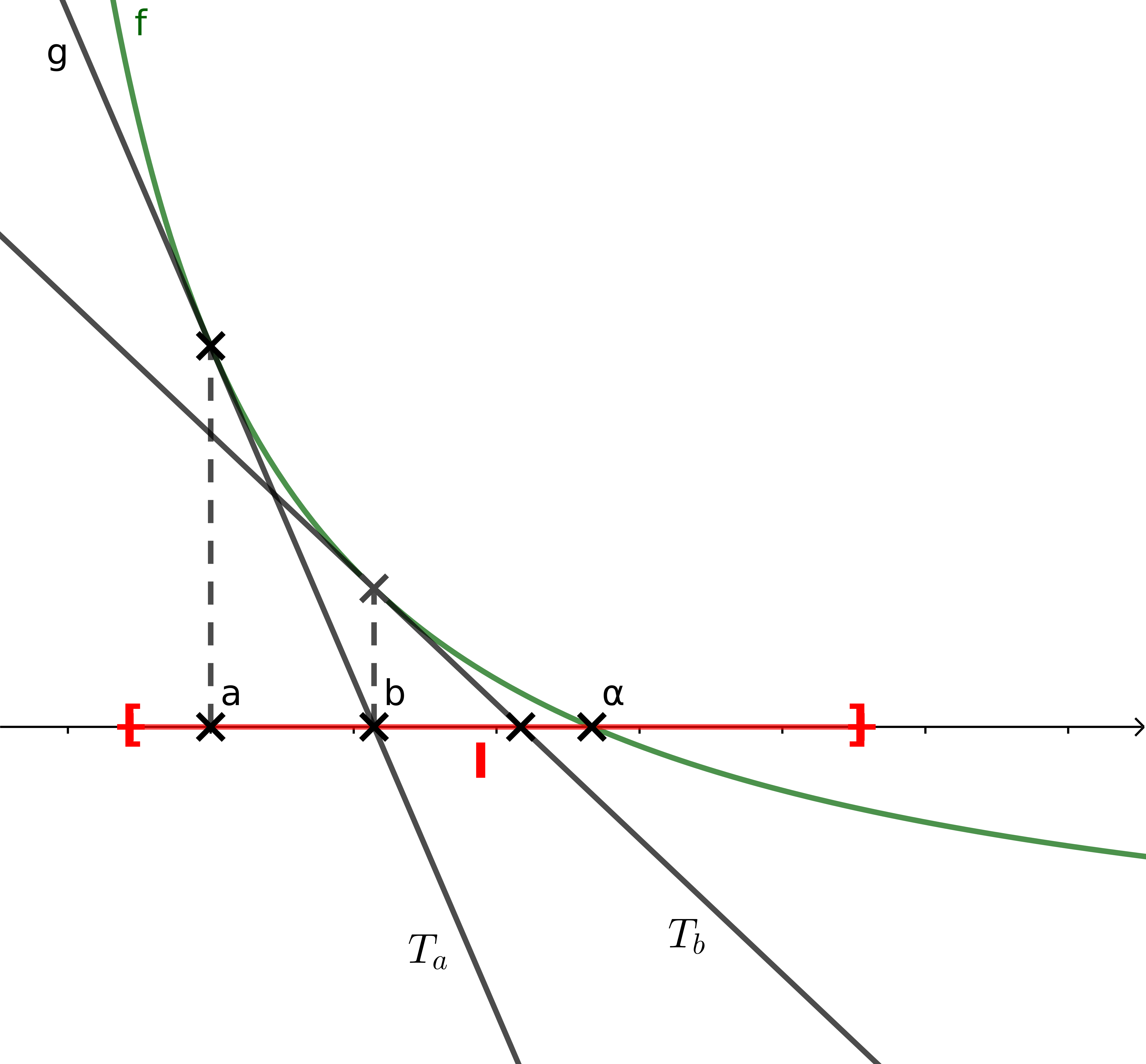
Une lectrice avertie m’a fait une remarque qui m’amène à vous proposer une autre version :
def f(x):
return x**3-3
def derivee_f(x):
return 3*x**2
def newton(fonction,derivee,x0,e):
x = x0
while abs(fonction(x))>e:
d=derivee(x)
x = x-fonction(x)/d
return xUtilisation :
>>> newton(f,derivee_f,2,1e-6)
1.4422495775224462
– si l’on doit se contenter d’un calcul approché de ce nombre dérivé en prenant comme approximation $f’(a) \approx \frac{f(a + h) - f(a)}{h}$ avec h suffisamment petit.
def f(x):
return 7/(3*x)-1
def newton(f,x0,e,h):
x = x0
while abs(f(x))>e:
d = (f(x+h)-f(x))/h #on calcule une approximation du nombre dérivé en x
x = x-f(x)/d
return xUtilisation :
>>> newton(f,2,1e-6,1e-5)
2.333332932960443Construction de l’exponentielle par la méthode d’Euler.
Soit $f$ une fonction dérivable sur $\mathbf{R}$ et vérifiant $f(0) = 1$ et pour tout $x \in \mathbf{R}, f’(x) = f(x)$.
La méthode d’Euler consiste à construire une suite de points $(x_n ; y_n)$ telle que $y_n$ soit proche de $f(x_n)$. Ainsi le nuage de points $(x_n ; y_n)$ formera une approximation de la courbe représentative de la fonction $f$.
La suite $(x_n)$ est une suite arithmétique de raison $h>0$ et de premier terme 0, $h$ est appelé le pas. On a donc $x_n = nh$ et $x_{n+1}=x_n + h$.
La suite $(y_n)$ est définie par $y_0 = f(x_0) = f(0) = 1$ et pour tout $n \in \mathbf{N}, y_{n+1}=y_n+hf’(x_n)$. C’est-à-dire que l’on se sert de l’approximation affine de la fonction par ses tangentes successives.
$(y_n)$ est géométrique de premier terme 1 et de raison 1 + h, en effet $y_{n+1}=y_n+hf(x_n)=y_n+hy_n= (1 + h)y_n$.
D’où le script suivant :
import matplotlib.pyplot as plt
def Euler(x_f,n) :
x=0
y=1
h=x_f/n
abscisse=[0]
ordonnee=[1]
for i in range(n) :
y=(1+h)*y
x=x+h
abscisse.append(x)
ordonnee.append(y)
plt.plot(abscisse,ordonnee,"r")
plt.show()Utilisation, pour un nuage de n=100 points pour x allant de 0 à x_f=5 :
>>> Euler(5,100)Ce qui donne le graphique suivant :

Et si l’on veut comparer avec le « vrai » graphe de la fonction exponentielle :
import matplotlib.pyplot as plt
from math import exp
def Euler(x_f,n) :
x=0
y=1
h=x_f/n
abscisse=[0]
ordonnee=[1]
expo=[1]
for i in range(n) :
y=(1+h)*y
x=x+h
abscisse.append(x)
ordonnee.append(y)
expo.append(exp(x))
plt.plot(abscisse,ordonnee,"r")
plt.plot(abscisse,expo,"b")
plt.show()

Approximation de π par la méthode d’Archimède
Pour approcher π, on peut s’intéresser aux périmètres des polygones réguliers à n côtés inscrits et circonscrits au cercle de diamètre 1 :

Le principe de l’algorithme d’Archimède est le suivant :
Soit $p_n$ le périmètre d’un polygone régulier de n côtés inscrit dans un cercle de rayon $\frac 1 2$. Archimède observe que : $\displaystyle{\lim_{n \to +\infty} p_n = \pi}$ et il évalue la limite au moyen de la suite $p_6, p_{12}, p_{24}, p_{48} ...$ obtenue par doublements successifs du nombre de côtés. Soit $u_n = \frac 1 n p_n$ la longueur du côté d’un n-gone.
L’hexagone inscrit a pour côté $\frac 1 2$ et pour périmètre 3.
Si l’on appelle $u_n$ la longueur du côté du polygone à n côtés et $u_{2n}$ la longueur du côté du polygone à 2n côtés, nous obtenons ceci :
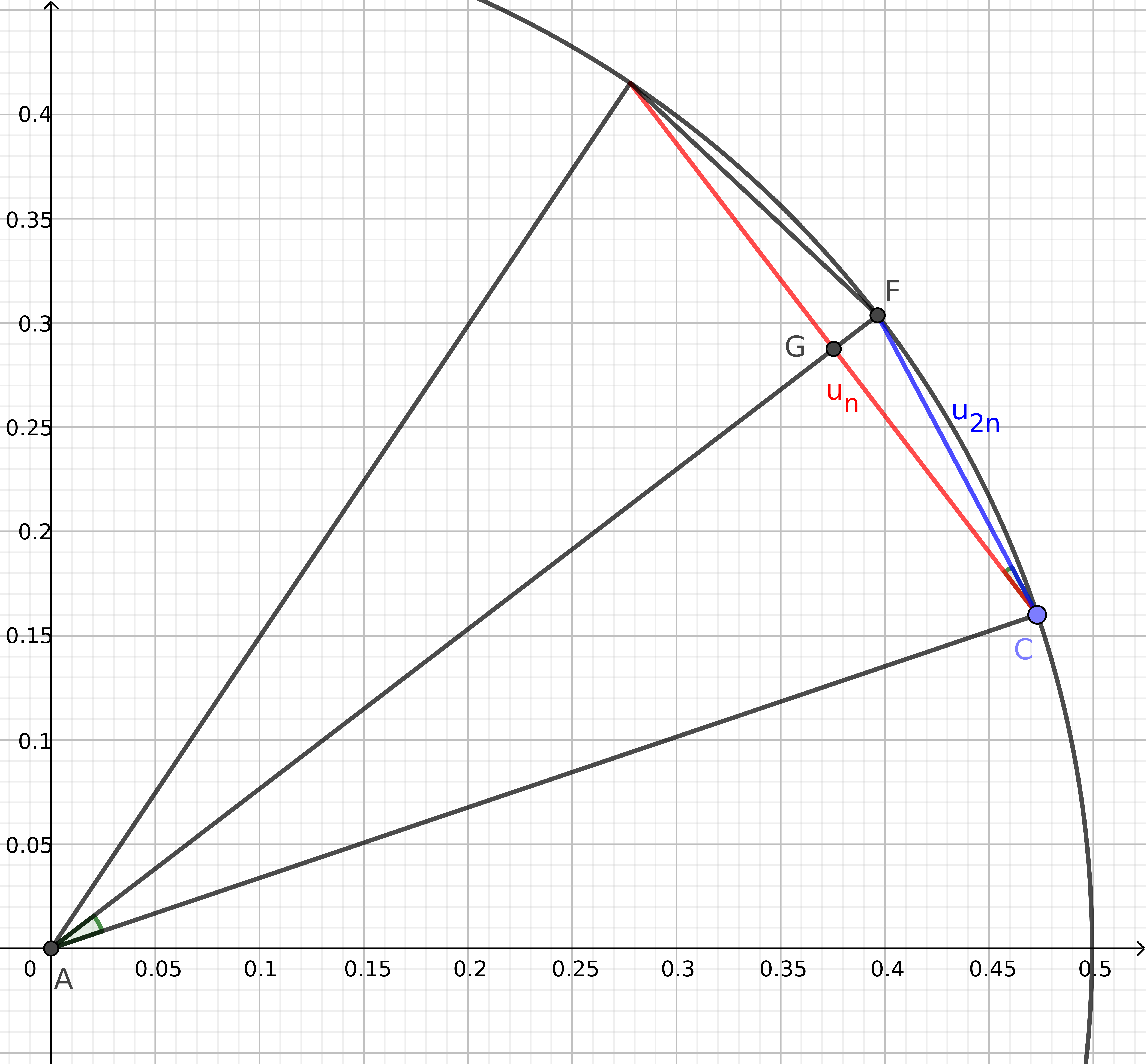
Le triangle ACG est rectangle en G, et la somme des angles dans le triangle ACF, isocèle en A, conduit à l’égalité suivante :
$\widehat{CAF} + 2\times\widehat{ACF} = \pi$, d’où $\widehat{CAF} + 2(\frac{\pi}{2} - \widehat{CAF} + \widehat{GCF}) = \pi$, et finalement $2\widehat{GCF} = \widehat{CAF}$.
Dans le triangle GCF rectangle en G, on a $\cos\widehat{GCF} = \frac{\frac{u_n}{2}}{u_{2 n}}$ et dans le triangle GCA rectangle en G, on a $\sin\widehat{GAC} = \frac{\frac{u_n}{2}}{\frac 1 2}$, d’où $\sin\widehat{CAG} = u_n$. De plus $\cos\widehat{GCF} = \cos{\frac{\widehat{CAF}}{2}} = \sqrt{\frac{1+\cos{\widehat{CAF}}}{2}} = \sqrt{\frac{1+\sqrt{1 - \sin^2{\widehat{CAF}}}}{2}} = \sqrt{\frac{1+\sqrt{1 - {u_n}^2}}{2}}$, donc $\frac{\frac{u_n}{2}}{u_{2 n}} = \sqrt{\frac{1+\sqrt{1 - {u_n}^2}}{2}}$, ainsi ${u_{2 n}} = \frac{\frac{u_n}{2}}{\sqrt{\frac{1+\sqrt{1 - {u_n}^2}}{2}}}$, finalement $u_{2 n} = \sqrt{\frac 1 2 \left(1-\sqrt{1 - {u_n}^2}\right)}$.
On peut maintenant passer à la programmation :
from math import sqrt
def archimede(n):
nb_cotes=6
u=0.5
p=3
for i in range(n):
u=sqrt(0.5*(1-sqrt(1-u**2)))
nb_cotes=6*2**(i+1)
p=nb_cotes*u
return nb_cotes,pUtilisation : La fonction renvoie le nombre de côtés du polygone et son périmètre. Elle prend en paramètre la valeur de n pour obtenir le polygone $p_{6\times 2^n}$. Archimède avait fait le calcul pour $n = 4$, c’est-à-dire pour 96 côtés.
>>> archimede(4)
(96, 3.14103195089053)
>>> archimede(5)
(192, 3.1414524722853443)
>>> archimede(11)
(12288, 3.1415926186407894)
>>> archimede(12)
(24576, 3.1415926453212157)
>>> archimede(13)
(49152, 3.1415926453212157)
>>> archimede(14)
(98304, 3.1415926453212157)
>>> archimede(15)
(196608, 3.1415926453212157)
>>> archimede(16)
(393216, 3.141593669849427)Le programme rencontre un problème pour n>=12, le résultat est le même (à l’affichage) et ne donne pas les bonnes décimales de pi, au-delà de 16 la suite diverge, puis deviens nulle ...
Géométrie
Il n’y a pas d’algorithme explicitement indiqué dans le programme pour cette partie. Aussi nous nous permettons de vous proposer celui-ci :
Le triangle de Sierpinski
Le triangle de Sierpiński est une fractale.
Il est défini de la manière suivante : on part d’un triangle équilatéral « plein » que l’on partage en quatre triangles équilatéraux et dont on enlève le triangle central. On recommence l’opération pour les triangles restants et ainsi de suite. Pour des raisons liées à la programmation, nous allons juste inverser le « plein » et le « vide », ce qui devient : on part d’un triangle équilatéral « vide » que l’on partage en quatre triangles équilatéraux et dont on colore le triangle central. On recommence l’opération pour les triangles vides restants et ainsi de suite.
Les figures ci-dessous donnent le rang 0 et les deux premières étapes :
|
|
|



Nous allons nous intéresser à la programmation de l’algorithme qui produit ces figures. Il nous faut donc tracer un triangle équilatéral, et pour cela, il va nous falloir le faire à partir des coordonnées de ces sommets afin de réitérer l’opération :
import matplotlib.pyplot as plt
def triangle(A,B,C):
sommet1=A
sommet2=B
sommet3=C
x=[sommet1[0],sommet2[0],sommet3[0],sommet1[0]]
y=[sommet1[1],sommet2[1],sommet3[1],sommet1[1]]
plt.plot(x,y,"r")Ce programme trace les segments [AB], [BC] et [CA] donc le triangle ABC.
Pour avoir la même chose mais coloriée :
def triangle_plein(A,B,C):
sommet1=A
sommet2=B
sommet3=C
x=[sommet1[0],sommet2[0],sommet3[0],sommet1[0]]
y=[sommet1[1],sommet2[1],sommet3[1],sommet1[1]]
plt.fill(x,y,"r")Nous avons également besoin du calcul des coordonnées du milieu d’un segment afin d’itérer le processus :
def milieu(A,B):
return [(A[0]+B[0])/2,(A[1]+B[1])/2]Dans la suite, nous allons appliquer une démarche récursive : on part de l’étape n (inconnue) et on la décrit en fonction de l’étape n - 1, qui elle-même est décrite en fonction de l’étape n - 2 et ainsi de suite jusqu’à arriver à l’étape 1 connue. On parvient au résultat voulu en écrivant un algorithme qui s’appelle lui-même.
def triangle_serpienski(A,B,C,n):
if (n>0 and n<9):
E = milieu(A,B)
F = milieu(B,C)
G = milieu(C,A)
triangle_plein(E,F,G)
triangle_serpienski(A,E,G,n-1)
triangle_serpienski(E,B,F,n-1)
triangle_serpienski(G,F,C,n-1)
elif(n>=9):
return "Le nombre de calculs est trop important, vous devez donner 1<n<9"On prend soin d’éviter que le programme ne se bloque en raison d’un trop grand nombre de calculs.
Enfin, on gère l’ensemble du programme, en évitant l’affichage des axes et des graduations, non nécessaires :
def resultat(A,B,C,n):
fig,ax = plt.subplots()
triangle(A,B,C)
triangle_serpienski(A,B,C,n)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plt.show()Après avoir calculé les coordonnées des sommets du triangle initial, par exemple $A\left(-\frac 1 2 ; 0\right)$,$B\left(0 ; \frac{\sqrt{3}}{2}\right)$ et $C\left(\frac 1 2 ; 0\right)$.
Utilisation :
>>> from math import sqrt
>>> resultat([-1/2,0],[0,sqrt(3)/2],[1/2,0],7)

- Sierpinski7
On pourra compléter l’activité avec une feuille de calcul pour conjecturer le comportement des suites $(p_n)$ le périmètre de la surface colorée à l’étape n et $(a_n)$ l’aire de la surface colorée (ou blanche) à l’étape n.

- Triangles de Sierpinski
Et démontrer tout cela mathématiquement.
Probabilités et statistiques
Méthode de Monte-Carlo : estimation de l’aire sous la parabole, estimation du nombre π.
Cette méthode est proche de l’expérience de l’aiguille de Buffon.
Soit un point M de coordonnées $(x, y)$, où $0 < x < 1$ et $0 < y < 1$. On tire aléatoirement les valeurs de x et y entre 0 et 1 suivant une loi uniforme. Le point M appartient au disque de centre (0,0) de rayon R=1 si et seulement si $x^2 + y^2 ≤1$. La probabilité que le point M appartienne au disque est $\frac \pi 4$, puisque le quart de disque est de surface $\sigma=\frac{\pi R^2} 4=\frac \pi 4$, et le carré qui le contient est de surface $S = R^2 = 1$ : si la loi de probabilité du tirage de point est uniforme, la probabilité de tomber dans le quart de disque vaut $\frac \sigma S = \frac \pi 4$.
En faisant le rapport du nombre de points dans le disque au nombre de tirages, on obtient une approximation du nombre $\frac \pi 4$ si le nombre de tirages est grand.
import matplotlib.pyplot as plt
from matplotlib import patches
from random import *
from math import sqrt
from math import pi
def distance(x,y):
return sqrt(x**2+y**2)
def monte_carlo(n):
#dessin du cercle
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
centreCircle = plt.Circle((0,0),1,color="red",fill=False) #
ax.add_patch(centreCircle)
#dessin des points
c=0
for i in range(n):
a,b = random(),random()
if distance(a,b)<=1:
c+=1
plt.plot(a,b,"r.")
else:
plt.plot(a,b,"b.")
plt.axis("equal")
plt.axhline(color='g') #l'axe (Ox)
plt.axvline(color='g') #et (Oy)
plt.title("Métode de Monte Carlo")
texte1="Nombre de points dans le cercle/Nombre de points = ",c/n
plt.text(-1.1,-0.3,texte1)
texte2="Valeur approchée de pi/4 = ",round(pi/4,5)
plt.text(-1.1,-0.5,texte2)
plt.grid()
plt.show()
return c/nUtilisation :
>>> monte_carlo(5000)
0.7804

Pour calculer l’aire sous la parabole de la fonction carré entre 0 et 1, on adapte le script précédent :
import matplotlib.pyplot as plt
from random import *
def monte_carlo_parabole(n):
#dessin de la parabole
x,y=[],[]
for i in range(51):
x.append(i/50)
y.append(i**2/2500)
plt.plot(x,y,"r-")
#dessin des points
c=0
for i in range(n):
a,b = random(),random()
if b<a**2:
c+=1
plt.plot(a,b,"r.")
else:
plt.plot(a,b,"b.")
plt.axis("equal")
plt.axhline(color='g') #l'axe (Ox)
plt.axvline(color='g') #et (Oy)
plt.title("Métode de Monte Carlo")
texte1="Nombre de points sous la parabole/Nombre de points = ",c/n
plt.text(-0.2,0.7,texte1)
plt.grid()
plt.show()
return c/nUtilisation :
>>> monte_carlo_parabole(3000)
0.334

Fréquence d’apparition des lettres d’un texte donné, en français, en anglais.
S’intéresser à la fréquence d’apparition des lettres dans un texte sert principalement à déchiffrer un texte codé par substitution. Cette technique n’est plus utilisée car elle ne résiste pas à l’analyse fréquentielle et à la puissance des ordinateurs. On arrive, après analyse fréquentielle et différents tests à retrouver le texte initial. Plusieurs options, pour le chiffrement comme pour le décodage, sont possibles :
– prise en compte ou pas de la ponctuation ;
– remplacement ou suppression des caractères accentués ; [1]
– prise en compte des chiffres ;
– remplacement ou suppression des ç, €, %, &, (),[], œ, ...
Le type de document analysé a aussi son importance, si c’est un texte technique, un roman, un texte narratif. Sa longueur est également un critère important, plus il est long, plus il est théoriquement sensé donner des fréquences correspondant au modèle, nous utiliserons le résultat suivant, pour un texte en langue française :
e:14,2% ; a:8,3% ; i:7,7% ; s:7,6% ; n:7,5% ; r:7,1% ; t:6,9% ; o:5,9% ; l:5,8% ; u:5,3% ; d:4,3% ; c:3,7% ; m:3,1% ; p:2,9% ; g:1,4% ; b:1,3% ; v:1,3% ; h:1,3% ; f:1,3% ; q:0,8% ; y:0,5% ; x:0,4% ; j:0,4% ; k:0,3% ; w:0,2% ; z:0,2%.
Nous nous intéresserons donc à des textes codés uniquement avec des lettres minuscules.
Soit le texte codé suivant :
Tous les caractères autres que ceux de l’alphabet classique ont été enlevés et les majuscules ont été remplacées par des minuscules à l’aide des deux fonctions suivantes :
# encoding: utf-8
import unicodedata
#Ce module donne accès à la base de données des caractères Unicode
#ce qui permet de convertir les caractères accentués
def nettoyage(texte):
if ".txt" in texte:
fichier=open(texte,'r')
texte=fichier.read()
fichier.close()
texte = unicodedata.normalize('NFKD', texte).encode('ascii','ignore').decode()
alphabet="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
nbcar=len(texte)
texteformate=""
for k in range(nbcar):
j=0
trouve=0
while (j<len(alphabet)) and (trouve==0):
if texte[k]==alphabet[j]:
trouve=1
if trouve==0:
j+=1
if trouve==1:
texteformate+=texte[k]
return(texteformate)
def minuscules(texte):
nbcar=len(texte)
texteformate=""
for k in range(nbcar):
if ord(texte[k])<97:
texteformate+=chr(ord(texte[k])+32)
else:
texteformate+=texte[k]
return(texteformate)Utilisation :
>>> minuscules(nettoyage("Fréquence d’apparition des lettres d’un texte donné"))
'frequencedapparitiondeslettresduntextedonne'Pour illustrer notre propos, nous avons utilisé un texte plus long, enregistré dans un fichier texte nommé « texte_analyse.txt » avec le code suivant :
>>> minuscules(nettoyage("texte_analyse.txt"))Le texte a ensuite été transformé (le résultat est dans le cadre ci-dessus) à l’aide d’un chiffrement affine qui peut ne pas être expliqué aux élèves, selon le script suivant :
def codage_affine(texte,m,p):
textecode=""
nbcar=len(texte)
for k in range(nbcar):
u=ord(texte[k])-97
v=m*u+p
w=v%26
t=chr(97+w)
textecode+=t
return(textecode)Le code ci-dessus transforme le code ascii de chaque lettre en un nombre compris entre 0 et 25, ce nombre est transformé par la fonction affine $f(x) = mx + p$, puis ramené à un nombre compris entre 0 et 25, transformé en code ascii d’une lettre minuscule en ajoutant 97. Ce codage affine ne fonctionne pas si m et 26 ne sont pas premiers entre eux car plusieurs lettres sont alors codées par la même lettre. Si $m=1$, on retrouve le chiffrement de César qui consiste en un simple décalage des lettres (a -> e, b ->f, c ->g, ...).
Cette fonction sert aussi de fonction de décodage, en effet si $y \equiv mx + p [26]$ alors $y - p \equiv mx [26]$ et $x \equiv m^{-1}y - m^{-1}p [26]$ où $m^{-1}$ est tel que $mm^{-1} \equiv 1 [26]$, c’est-à-dire que $m^{-1}$ est l’inverse modulaire de $m$ modulo 26 (Par exemple : 9 est l’inverse modulaire de 3 car $9\times 3 = 27 \equiv 1 [26]$). On peut alors décoder le texte avec codage_affine(texte,$m^{-1},- m^{-1}p$).
Procédons maintenant au décryptage du texte codé, commençons par l’analyse fréquentielle d’apparition des lettres dans ce texte, à l’aide du script suivant :
def analyse_frequence_lettre(texte,lettre):
nbcar=len(texte)
compteur=0.0
for k in range(nbcar):
if texte[k]==lettre:
compteur+=1
freq=round(compteur/nbcar,3)
return(freq)
def analyse_frequence_alphabet(texte):
alphabet="abcdefghijklmnopqrstuvwxyz"
frequences=[]
for lettre in alphabet:
frequences.append([lettre,analyse_frequence_lettre(texte,lettre)])
return(frequences)Utilisation :
>>> analyse_frequence_alphabet("slylsfnxakxhtxyqjxssxbtlylsfnxuxakxhtxyrxnxnq...")
[['a', 0.023], ['b', 0.04], ['c', 0.008], ['d', 0.009], ['e', 0.032], ['f', 0.012], ['g', 0.012],
['h', 0.017], ['i', 0.0], ['j', 0.064], ['k', 0.062], ['l', 0.069], ['m', 0.0], ['n', 0.082],
['o', 0.008], ['p', 0.001], ['q', 0.081], ['r', 0.035], ['s', 0.065], ['t', 0.053], ['u', 0.033],
['v', 0.024], ['w', 0.006], ['x', 0.202], ['y', 0.063], ['z', 0.001]]Au vu des résultats ci-dessus, on conjecture que c’est la lettre « x » qui code la lettre « e », on procède alors au changement de la lettre « x » par la lettre « e » dans le texte codé, sauf que si on fait cela on ne va plus distinguer le « e » codé du « e » décodé, on va donc procéder au changement de la lettre « x » par la lettre « E » dans le texte codé afin de faire la distinction. Ceci à l’aide du code suivant :
def change_lettre(texte,lettre1,lettre2):
texte=texte.replace(lettre1,lettre2)
return(texte)Ce qui donne comme résultat :
>>> change_lettre("slylsfnxakxhtxyqjxssxbtlylsfnxuxakxhtxyrxnxnq...","x","E")
'slylsfnEakEhtEyqjEssEbtlylsfnEuEakEhtEyrEnEnqtyEvEqgbuEuErkfeqlyl...'Rien dans le résultat ne nous permet de dire si cette conjecture est vraie ou fausse, continuons en gardant cette permutation.
On conjecture alors que c’est la lettre « n » qui code la lettre « a », on procède au changement de lettre dans le texte et on obtient :
>>> change_lettre("slylsfnEakhtEyqjEssEbtlylsfnEuEakhtEyrEnEnqtyEvqg...","n","A")
'slylsfAEakhtEyqjEssEbtlylsfAEuEakhtEyrEAEAqtyEvqgb...'La suite de lettre « EAEA » nous laisse à penser que ce n’est pas la bonne solution.
On conjecture alors que c’est la lettre « q » qui code la lettre « a », on procède au changement de lettre dans le texte et on obtient :
>>> change_lettre("slylsfnEakhtEyqjEssEbtlylsfnEuEakhtEyrEnEnqtyEvqg...","q","A")
'slylsfnEakEhtEyAjE...nulyntyvEnnldErgjaakErEAAEvEAgbu...'La suite de lettre « EAAE » nous laisse à penser que ce n’est pas la bonne solution.
On conjecture alors que c’est la lettre « l » qui code la lettre « a », on procède au changement de lettre dans le texte et on obtient :
>>> change_lettre("slylsfnEakhtEyqjEssEbtlylsfnEuEakhtEyrEnEnqtyEvqg...","l","A")
'sAyAsfnEakEhtEyqjEssEbtAyAsfnEuEakEhtEyrEnEnqtyEvEqgbuEuErkfeqA...'Rien dans le résultat ne nous permet de dire si cette conjecture est vraie ou fausse, continuons en gardant cette permutation.
Et ainsi de suite, jusqu’au résultat final :
>>> change_lettre("LANALYSEFREhUENTIELLEOUANALYSEDEFREhUENCE...","h","Q")
"LANALYSEFREQUENTIELLEOUANALYSEDEFREQUENCESESTUNEMETHODEDE ..." En rajoutant « à la main » les espaces et la ponctuation :
« L’ANALYSE FRÉQUENTIELLE OU ANALYSE DE FRÉQUENCES EST UNE METHODE DE ... »

- Le fichier qui contient le texte initial en français.
Pour un texte en Anglais :
la procédure est exactement la même avec le tableau des fréquences d’apparition des lettres en Anglais :
| A | B | C | D | E | F | G | H | I | J | K | L | M |
| 8,08% | 1,67% | 3,18% | 3,99% | 12,56% | 2,17% | 1,80% | 5,27% | 7,24% | 0,14% | 0,63% | 4,04 % | 2,60% |
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 7,38% | 7,47% | 1,91% | 0,09% | 6,42% | 6,59% | 9,15% | 2,79% | 1,00% | 1,89% | 0,21% | 1,65% | 0,07% |
Donc les lettres les plus fréquentes arrivent dans cet ordre : ETAONISRH ...
Soit le texte suivant à décoder :
On obtient alors :
>>> analyse_frequence_alphabet('gafesxgdtxqhzgxmadjcfghzeshqrfadjcfgxmyf...')
[['a', 0.064], ['b', 0.014], ['c', 0.04], ['d', 0.085], ['e', 0.017], ['f', 0.114], ['g', 0.093],
['h', 0.072], ['i', 0.002], ['j', 0.027], ['k', 0.01], ['l', 0.001], ['m', 0.023], ['n', 0.024],
['o', 0.001], ['p', 0.011], ['q', 0.078], ['r', 0.025], ['s', 0.073], ['t', 0.028], ['u', 0.009],
['v', 0.009], ['w', 0.0], ['x', 0.072], ['y', 0.036], ['z', 0.075]]On procède alors au changement de lettres « f » -> « E », « g » -> « T » et « d » -> « A » qui ne montrent pas d’incohérences. En suivant l’ordre logique, le changement suivant est « q » -> « O » et, en cherchant des incohérences, je constate que si on remplace « a » par « H », on voit apparaitre de nombreux « THE » et « THAT », ce qui semble être une bonne chose, le texte « TAOAO » m’incite à procéder au changement « q » -> « N ». Le texte présente de nombreux « zz » voire « zzz » ce qui conduit à procéder au changement « z » -> « S » puis « h » -> « I », « x » -> « O » et « s » -> « R ». On a alors placé toutes les lettres aux fréquences les plus importantes. On intuite ensuite les changements « e » -> « P », « t » -> « G », « j » -> « M », « c » -> « L », « y » -> « D », « p » -> « Y », « v » -> « K », « b » -> « W », « n » -> « U », « l » -> « Q », « o » -> « J », « i » -> « X » en complétant des mots partiellement découverts.
- Le fichier qui contient le texte initial en anglais.
Algorithmique et programmation
Bibliographie
- Les algorithmes et les scripts en Python pour la classe de Seconde (2019) ;
- Les algorithmes du programme de Mathématiques de Première technologique (2019) ;
- Quelques précisions données par l’Inspection Générale concernant l’écriture des programmes Python au lycée.
- Algorithmique et programmation au cycle 4, Commentaires et recommandations du groupe Informatique de la CII Lycée
- Les articles sur Python dans MathémaTICE
- Parcours Magistère : Algorithmique/Programmation au Lycée : Python
- Représentation binaire des Nombres Réels