N.D.L.R. Dans l’article que voici, Benjamin Clerc continue de passer en revue les algorithmes introduits par la réforme de 2019 des programmes de Lycée. Pour mémoire :
- Les algorithmes du programme 2019 de mathématiques de Seconde
- Les algorithmes du programme de spécialité mathématiques de Première (2019).
- Les algorithmes du programme de Mathématiques de Première technologique (2019).
- Mathématiques complémentaires : les algorithmes du programme de l’option de Terminale (2020)
- Les algorithmes du programme de l’option de Terminale « Mathématiques expertes » (2020)
Il convient d’y ajouter
- Cet article d’Alain Busser
- Et celui de Matthieu Brabant au sujet du Lycée Professionnel.
L’article qui suit a été complété et enrichi par les suggestions et l’apport de Cyrille Guieu.
Cet article peut être librement diffusé et son contenu réutilisé pour une utilisation non commerciale (contacter l’auteur pour une utilisation commerciale) suivant la licence CC-by-nc-sa.
Programme de spécialité de mathématiques de terminale générale (BO de l’Éducation Nationale)
Algèbre et géométrie
Analyse
Recherche de valeurs approchées de $\pi, e, \sqrt{2}, \frac{1 + \sqrt{5}}{2}, ln(2),$ etc.
Valeur approchée de 𝜋
Nous avons déjà approximé 𝜋 en classe de première avec la méthode d’Archimède et la méthode de Monte Carlo, nous utiliserons en Terminale la formule de Bellard :
$\displaystyle \pi ={\frac {1}{2^{6}}}\sum _{n=0}^{\infty }{\frac {(-1)^{n}}{2^{10n}}}\left(-{\frac {2^{5}}{4n+1}}-{\frac {1}{4n+3}}+{\frac {2^{8}}{10n+1}}-{\frac {2^{6}}{10n+3}}-{\frac {2^{2}}{10n+5}}-{\frac {2^{2}}{10n+7}}+{\frac {1}{10n+9}}\right)$
def bellard(n):
pi=0
for i in range(n+1):
pi+=(-2**5/(4*i+1)-1/(4*i+3)+2**8/(10*i+1)-2**6/(10*i+3)-2**2/(10*i+5)-2**2/(10*i+7)+1/(10*i+9)) *(-1)**i/(2**6*2**(10*i))
return piUtilisation :
>>> bellard(3)
3.1415926535897545
>>> bellard(4)
3.1415926535897922A noter que Python ne peut faire mieux que bellard(4) qui n’est pas une bonne approximation puisque les 3 dernières décimales sont erronées. En utilisant le module Decimal, on obtient deux décimales exactes de plus, pas plus ...
Valeur approchée de e
Une valeur approchée de e (nombre d’Euler, ou nombre Népérien) peut être calculée en utilisant la formule suivante :
$e \approx 1 + \frac{1}{1 !} + \frac{1}{2 !} + \frac{1}{3 !} + ... + \frac{1}{n !}$
Avec une fonction factorielle :
def factorielle(n):
if n==0:
return 1
else:
return n*factorielle(n-1)
def calcul_e(n):
if n==0:
return 1
else:
return calcul_e(n-1)+1/factorielle(n)Utilisation :
>>> calcul_e(2)
2.5
>>> calcul_e(3)
2.6666666666666665
>>> calcul_e(20)
2.7182818284590455Pour ceux qui préfèrent une version non récursive de la fonction factorielle :
def factorielle(n):
if n==0:
return 1
else:
resultat=1
for i in range(1,n+1):
resultat*=i
return resultatValeur approchée de $\sqrt{2}$
On doit à Théon de Smyrne ces deux suites $(p_n)$ et $(q_n)$ définies par récurrence :
$p_{n + 1} = p_n + 2q_n, p_0 = 1$ ;
$q_{n + 1} = p_n + q_n, q_0 = 1$.
Ces suites sont à valeur entière strictement positive, donc strictement croissantes par récurrence, et vérifient :
$p_n² − 2q_n² = (−1)^n(p_0² − 2q_0²)$ de sorte que $\frac{p_n}{q_n}$ tend vers $\sqrt{2}$.
def racine2(n):
p,q=1,1
for i in range(n):
p,q=p+2*q,p+q
return p/qUtilisation :
>>> racine2(10)
1.4142135516460548
>>> racine2(100)
1.4142135623730951Valeur approchée de $\frac{1 + \sqrt{5}}{2}$
La suite de Fibonacci $(Fn)$ est définie par récurrence :
$F_1 = F_2 = 1$ et $F_{n + 2} = F_{n + 1} + F_n$ .
Une de ses propriétés est que ${\displaystyle\varphi =\lim _{n\to \infty }{\frac {F_{n+1}}{F_{n}}}}$
def nombredor(n):
p,q=1,1
for i in range(n):
p,q=q,p+q
return q/pUtilisation :
>>> nombredor(10)
1.6179775280898876
>>> nombredor(20)
1.618033985017358
>>> nombredor(39)
1.618033988749895Valeur approchée de $\sqrt{3}$
Chez les mathématiciens grecs, extraire la racine carrée de a revient à trouver un carré dont l’aire soit a. En prenant un rectangle de côté arbitraire x et de même aire, il est nécessaire que l’autre côté ait pour longueur $\frac{a}{x}$. Pour le rendre « moins rectangle », il suffit de considérer un nouveau rectangle dont la longueur est la moyenne arithmétique des deux côtés précédents soit $\frac {x+\frac{a}{x}}{2}$ et dont l’aire reste a.
En réitérant infiniment le processus, le rectangle se transforme petit à petit en un carré de même aire. Cette constatation est à la base de la méthode de Héron.
On crée une fonction qui prend en paramètres le nombre a dont on veut calculer la racine, le nombre x, strictement positif qui est la longueur du côté du rectangle de départ et le nombre n qui est le nombre de fois où l’on réitère l’opération.
def Heron(a,x,n):
for i in range(n):
x=(x+a/x)/2
return xUtilisation :
>>> Heron(3,1,10)#On peut ainsi calculer une approximation de racine de 3
1.7320508075688772
>>> Heron(2,1,8)#On peut aussi calculer une approximation de racine de 2
1.414213562373095Toutes les approximations de $\sqrt{3}$ ainsi obtenues sont des fractions que l’on peut avoir envie de « voir » :
from fractions import *
def Heron2(a,x,n):
x= Fraction(x)
for i in range(n):
x=(x+3/x)/2
return xUtilisation :
>>> for i in range(7):
Heron2(3,1,i)
Fraction(1, 1)
Fraction(2, 1)
Fraction(7, 4)
Fraction(97, 56)
Fraction(18817, 10864)
Fraction(708158977, 408855776)
Fraction(1002978273411373057, 579069776145402304)L’algorithme de Heron est suffisamment rapide pour calculer presque instantanément des centaines de décimales de $\sqrt{3}$ :
from decimal import *
def Heron3(a,x,n):
getcontext().prec=n+1
x=Decimal(x)
for i in range(10):#Changer ce 10 pour davantage de decimales cherchées
x=(x+Decimal(a)/x)/2
return xUtilisation :
>>> Heron3(3,1,400)
Decimal('1.732050807568877293527446341505872366942805253810380628055806979451933016908800037081146186
75724857567562614141540670302996994509499895247881165551209437364852809323190230558206797482010108467
49232650153123432669033228866506722546689218379712270471316603678615880190499865373798593894676503475
06576050756618348129606100947602187190325083145829523959832997789824508288714463832917347224163984587
8553976')Vous pouvez vérifier ici.
Valeur approchée de $\ln{2}$
En écrivant $\ln(2)=\int_{1}^{2} \frac{1}{t}dt$ et en subdivisant de manière de plus en plus fine l’intervalle [1 ; 2] pour approcher cette intégrale par une somme de Riemann.
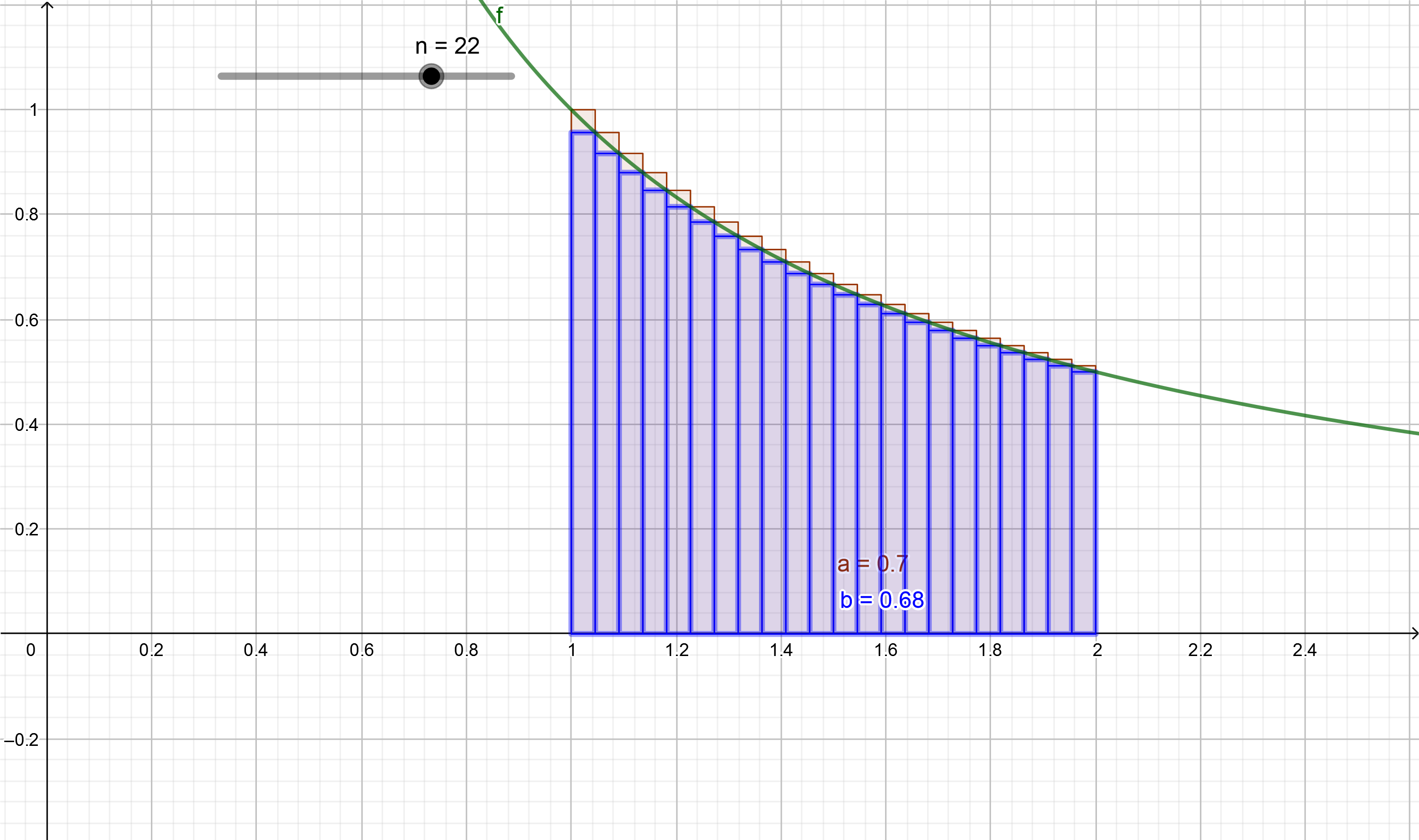
Nous verrons cela plus loin dans l’article.
Nous allons donc calculer $ln(2)$ au moyen de la série harmonique alternée : ${\displaystyle \ln(2) =\lim _{n\to \infty }\left(\sum _{k=1}^{n}{\frac {(-1)^{k + 1}}{k}}\right)}$
def ln2(n):
ln2=0
for i in range(1,n+1):
ln2+=(-1)**(i+1)/i
return ln2Utilisation :
>>> ln2(1000)
0.6926474305598223
>>> ln2(10000)
0.6930971830599583Cela converge très lentement puisque $\ln(2) \approx 0.69314718056$ ...
Valeur approchée de $\gamma$, la constante d’Euler-Mascheroni
La constante d’Euler-Mascheroni est une constante mathématique, utilisée principalement en théorie des nombres, définie comme la limite de la différence entre la série harmonique et le logarithme naturel. On la note usuellement $\gamma$.
La constante d’Euler-Mascheroni est définie par : ${\displaystyle \gamma =\lim _{n\to \infty }\left(1+{\frac {1}{2}}+{\frac {1}{3}}+{\frac {1}{4}}+\dots +{\frac {1}{n}}-\ln(n)\right)}$.
Ou encore : ${\displaystyle \gamma =\lim _{n\to \infty }\left(\sum _{k=1}^{n}{\frac {1}{k}}-\ln(n)\right)}$
La constante peut également être définie sous la forme explicite d’une série (telle qu’elle fut d’ailleurs introduite par Euler) :
${\displaystyle \gamma =\sum _{k=1}^{\infty }\left[{\frac {1}{k}}-\ln \left(1+{\frac {1}{k}}\right)\right]}$
La série harmonique diverge, tout comme la suite de terme général ${\displaystyle \ln(n)}$, l’existence de cette constante indique que les deux expressions sont asymptotiquement liées.
En utilisant cette dernière expression :
from math import log
def gamma(n):
g=0
for i in range(1,n+1):
g+=1/i-log(1+1/i)
return gUtilisation :
>>> gamma(10)
0.5310729811698833
>>> gamma(100)
0.5722570007983613
>>> gamma(1000)
0.5767160812351261
>>> gamma(1000000)
0.5772151649020281La convergence est très lente, en effet $\gamma \approx 0,577 215 664 9$, on n’a donc que 6 décimales correctes pour $n = 10^6$.
Méthode de dichotomie.
Une méthode dichotomique est une méthode algorithmique de recherche où à chaque étape on coupe l’intervalle de recherche en deux parties, le but étant de diminuer l’intervalle de recherche.
On peut appliquer la méthode dichotomique à trois types de problèmes :
La recherche d’un nombre inconnu.
On peut programmer un jeu qui consiste à trouver un nombre entre 0 et 100 choisi aléatoirement par le programme :
from random import randrange
def DevineNombre():
nb_inconnu=randrange(0,101)
nb_coups=1
nb_propose=int(input("Proposez une valeur pour le nombre inconnu : "))
while nb_inconnu!=nb_propose:
nb_coups+=1
if nb_inconnu>nb_propose:
print("Votre nombre est plus petit que le nombre inconnu.")
nb_propose=int(input("Proposez une nouvelle valeur pour le nombre inconnu : "))
else:
print("Votre nombre est plus grand que le nombre inconnu.")
nb_propose=int(input("Proposez une nouvelle valeur pour le nombre inconnu : "))
print("Gagné en ",nb_coups," coups !")Utilisation :
>>> DevineNombre()
Proposez une valeur pour le nombre inconnu : 50
Votre nombre est plus petit que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 75
Votre nombre est plus grand que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 62
Votre nombre est plus petit que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 69
Votre nombre est plus grand que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 65
Votre nombre est plus petit que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 67
Votre nombre est plus petit que le nombre inconnu.
Proposez une nouvelle valeur pour le nombre inconnu : 68
Gagné en 7 coups !La dichotomie est ici dans la méthode de recherche du nombre, méthode que l’on peut programmer :
def RechercheAuto():
nb_inconnu=randrange(0,101)
a=0
b=100
nb_coups=1
while b>a+1:
nb_coups+=1
nb_propose=floor((a+b)/2)
if nb_propose<nb_inconnu:
a=nb_propose
else:
b=nb_propose
nb_propose=round(nb_propose)
print("La valeur inconnue est : ",nb_propose,", touvée en ",nb_coups," coups.")Résolution d’une équation du type f(x) = 0.
Soit f une fonction strictement monotone, continue et changeant de signe sur l’intervalle [a ; b], c’est-à-dire $f(a)f(b) < 0$. L’intervalle de recherche est [a ; b].
Exemples :
 |
 |
À chaque étape, on partage l’intervalle en deux en considérant le centre m de cet intervalle, ensuite suivant le signe de $f(m)$, on restreint l’intervalle de recherche à la moitié de l’intervalle précédent. Et on continue en appliquant à l’intervalle obtenu la même procédure qu’à l’intervalle précédent, et ainsi de suite …
La recherche de la solution s’arrête lorsque le centre du dernier intervalle obtenu est considéré comme étant suffisamment proche de la solution cherchée. Pour cela, on se réfère à une condition d’arrêt fixée au départ.
La précision ne porte pas sur $f(m)$ car $f(m) < \epsilon$ n’implique pas que m soit proche de $x_0$ où $f(x_0) = 0$.
def dichotomie(f,a,b,epsilon):
while b-a>epsilon:
m=(a+b)/2
if f(m)==0:
a=m
b=m
else:
if f(a)*f(m)<0:
b=m
else:
a=m
return aUtilisation
>>> def f(x):
return x**2-3*x+2
>>> dichotomie(f,1.6,2.6,0.000001)
1.9999996185302735Recherche d’un maximum.
La recherche d’un maximum pour une fonction donnée sur un intervalle [a ; b] où il y a un changement de variations et un seul .
Le principe de dichotomie se déroule de la manière suivante :
- On coupe l’intervalle de recherche en deux parties, suivant le milieu m de l’intervalle. Puis on détermine le milieu de chacun des deux intervalles formés m1 et m2.
- On calcule les valeurs atteintes par f au milieu de l’intervalle de recherche f(m), et au milieu des deux demi intervalles f(m1) et f(m2).
- Enfin, on compare f(m1) à f(m) et f(m2) à f(m) :
Si f(m1)>f(m) le maximum est dans l’intervalle [a ; m] qui a pour milieu m1 ;
Si f(m2)>f(m) le maximum est dans l’intervalle [m ; b] qui a pour milieu m2 ;
si aucun des cas précédents ne se produit, le maximum est dans l’intervalle [m1 ; m2] qui a pour milieu m. - On recommence au début et on s’arrête lorsque la longueur de l’intervalle obtenu est inférieur à la précision choisie, l’approximation du nombre où le maximum est atteint sera donné par le centre du dernier intervalle obtenu.
Pour la recherche d’un minimum, il faut juste adapter un peu l’algorithme :
Si f(m1)<f(m) le minimum est dans l’intervalle [a ; m] qui a pour milieu m1 ;
Si f(m2)<f(m) le minimum est dans l’intervalle [m ; b] qui a pour milieu m2 ;
si aucun des cas précédents ne se produit, le minimum est dans l’intervalle [m1 ; m2] qui a pour milieu m.
def extremum(f,a,b,epsilon,choix): while b-a>epsilon: m=(a+b)/2 m1=(a+m)/2 m2=(m+b)/2 if choix=="max": if f(m1)>f(m): b=m elif f(m2)>f(m): a=m else: a=m1 b=m2 elif choix=="min": if f(m1)<f(m): b=m elif f(m2)<f(m): a=m else: a=m1 b=m2 else: print("Tu dois indiquer si tu cherches un minimum ou un maximum !") break return aUtilisation :
>>> from math import sin >>> def f(x): return x**2-sin(x) >>> extremum(f,0,1,0.0000001,"min") 0.45018357038497925 >>> def f(x): return -x**2-sin(x) >>> extremum(f,-1,0,0.0000001,"max") -0.450183629989624
Méthode de Newton, méthode de la sécante
Méthode de Newton
Partant d’une abscisse $x_0$ que l’on choisit de préférence proche de la racine à trouver, on approche la fonction au premier ordre, autrement dit, on la considère asymptotiquement égale à sa tangente en ce point :
$f (x)\approx f(x_0) + f ′(x_0)(x − x_0) $ .
Partant de là, pour trouver un zéro de cette fonction d’approximation, il suffit de calculer l’intersection de la droite tangente avec l’axe des abscisses, c’est-à-dire résoudre l’équation affine :
$0 = f(x_0) + f ′(x_0)(x − x_0) $
On obtient alors un point $x_1$ qui en général a de bonnes chances d’être plus proche du vrai zéro de f que le point $x_0$ précédent. Par cette opération, on peut donc espérer améliorer l’approximation par itérations successives (voir illustration) : on approche à nouveau la fonction par sa tangente en $x_1$ pour obtenir un nouveau point $x_2$, etc.
Cette méthode requiert que la fonction possède une tangente en chacun des points de la suite que l’on construit par itération, par exemple il suffit que f soit dérivable.
Formellement, on part d’un point $x_0$ appartenant à l’ensemble de définition de la fonction et on construit par récurrence la suite :
$x_{k+1} = x_k - \frac{f(x_k)}{f’(x_k)}$
où f ’ désigne la dérivée de la fonction f. Le point $x_{k+1}$ est bien la solution de l’équation affine $f (x_k ) + f ′( x_k ) ( x − x_k ) = 0$

def Newton(f,derivee,x0,epsilon):
x=x0
while abs(f(x))>epsilon :
x=x-f(x)/derivee(x)
return xUtilisation :
>>> from math import sin
>>> from math import cos
>>> def f(x):
return x**2-sin(x)
>>> def derivee(x):
return 2*x-cos(x)
>>> Newton(f,derivee,0.5,0.0000001)
0.8767262153968663Bien que la méthode soit très efficace, certains aspects pratiques doivent être pris en compte. Avant tout, la méthode de Newton nécessite que la dérivée soit effectivement calculée. Dans les cas où la dérivée est seulement estimée en prenant la pente entre deux points de la fonction, la méthode prend le nom de méthode de la sécante.
Méthode de la sécante
En approchant la dérivée $f ’(x_k)$ par $\frac{f ( x_k ) − f ( x_{k − 1})}{ x_k − x_{k − 1}}$
def secante(f,x0,epsilon,h):
x=x0
while abs(f(x))>epsilon :
derivee=(f(x+h)-f(x))/h
x=x-f(x)/derivee
return xUtilisation :
>>> from math import sin
>>> def f(x):
return x**2-sin(x)
>>> secante(f,0.5,0.0000001,0.0001)
0.8767262155615625Résolution par la méthode d’Euler de $y’ = y$, et de $y’ = ay + b$.
En mathématiques, la méthode d’Euler est une procédure numérique pour résoudre par approximation des équations différentielles du premier ordre avec une condition initiale. C’est la plus simple des méthodes de résolution numérique des équations différentielles.
Pour h proche de 0, on a $y(a+h) \approx y(a) + h y’(a)$ .Nous allons utiliser cette approximation affine pour construire pas à pas une fonction vérifiant une équation différentielle du premier ordre et passant par un point donné $(x_0 ; y_0)$.
Soit l’équation différentielle définie par $y’=y$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $y_0$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + hy_0 = y_0(1 + h)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
def Euler(x0,xf,y0,n):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y*(1+h)
abscisse.append(x)
ordonnee.append(y)
return ordonneeUtilisation :
>>> Euler(0,3,1,30)
[1, 1.1, 1.2100000000000002, 1.3310000000000004, 1.4641000000000006, 1.6105100000000008, 1.771561000000001,
1.9487171000000014, 2.1435888100000016, 2.357947691000002, 2.5937424601000023, 2.853116706110003,
3.1384283767210035, 3.4522712143931042, 3.797498335832415, 4.177248169415656, 4.594972986357222,
5.054470284992944, 5.559917313492239, 6.115909044841463, 6.72749994932561, 7.400249944258172, 8.140274938683989,
8.954302432552389, 9.849732675807628, 10.834705943388391, 11.91817653772723, 13.109994191499954,
14.420993610649951, 15.863092971714948, 17.449402268886445]Le graphique ci-dessous est réalisé avec les données ci-dessus et les valeurs exactes.

Soit l’équation différentielle définie par $y’= ay + b$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $ay_0 + b$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + h (ay_0 + b)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
def Euler(x0,xf,y0,n,a,b):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y+h*(a*y+b)
abscisse.append(x)
ordonnee.append(y)
return ordonneeUtilisation :
>>> Euler(0,3,2,30,-0.5,0)
[2, 1.9, 1.805, 1.71475, 1.6290125, 1.547561875, 1.47018378125, 1.3966745921875001, 1.3268408625781252,
1.2604988194492188, 1.1974738784767578, 1.13760018455292, 1.080720175325274, 1.0266841665590103,
0.9753499582310597, 0.9265824603195068, 0.8802533373035314, 0.8362406704383548, 0.7944286369164371,
0.7547072050706152, 0.7169718448170844, 0.6811232525762302, 0.6470670899474187, 0.6147137354500477,
0.5839780486775453, 0.5547791462436681, 0.5270401889314846, 0.5006881794849104, 0.4756537705106649,
0.45187108198513165, 0.4292775278858751]

Et l’on peut généraliser le processus :
Soit l’équation différentielle définie par $y’=f(x,y)$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $f(x_0 ; y_0)$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + hf(x_0,y_0)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
La fonction « Euler » ci-dessous prend comme dernier argument une fonction de deux variables :
def Euler(x0,xf,y0,n,f):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y+h*f(x,y)
abscisse.append(x)
ordonnee.append(y)
return ordonneeOn peut tester la fonction précédente avec f définie par f(x,y)=-0.5y :
>>> def f(x,y):
... return -0.5*y
...
>>> Euler(0,3,2,30,f)
[2, 1.9, 1.805, 1.71475, 1.6290125, 1.547561875, 1.47018378125, 1.3966745921875001, 1.3268408625781252,
1.2604988194492188, 1.1974738784767578, 1.13760018455292, 1.080720175325274, 1.0266841665590103,
0.9753499582310597, 0.9265824603195068, 0.8802533373035314, 0.8362406704383548, 0.7944286369164371,
0.7547072050706152, 0.7169718448170844, 0.6811232525762302, 0.6470670899474187, 0.6147137354500477,
0.5839780486775453, 0.5547791462436681, 0.5270401889314846, 0.5006881794849104, 0.4756537705106649,
0.45187108198513165, 0.4292775278858751]Ce qui donne bien le résultat précédent comme on s’y attendait.
Méthodes des rectangles, des milieux, des trapèzes.
On note $(x_i)_{i \in\{0, ..., n\}}$ une subdivision de l’intervalle [a ; b] Avec $a=x_0 < x_1 < ... < x_n = b$ et pour tout $i \in \{0, ..., n\}, x_i=a+i{\frac {b-a}{n}}$.
Il y a plusieurs méthodes pour approcher l’aire sous la courbe d’une fonction continue à l’aide de rectangles, commençons par la méthode des rectangles à gauche :
On remplace $f$ par la valeur qu’elle prend sur le bord gauche de l’intervalle $[x_i ; x_{i + 1}]$ soit $f(x_i)$, l’aire est alors égale à $f(x_i)\times{\frac{b - a}{n}}$.

D’où l’algorithme suivant :
def rectangles_gauche(f,a,b,n):
h=(b-a)/n
L=0
for i in range(n):
L+=f(a+i*h)
return h*LUtilisation :
>>> rectangles_gauche(f,1,5,30)
24.54518518518518Pour la méthode des rectangles à droite il suffit d’un tout petit changement :

def rectangles_droit(f,a,b,n):
h=(b-a)/n
A=0
for i in range(1,n+1):
A+=h*f(a+i*h)
return AUtilisation :
>>> rectangles_droit(f,1,5,30)
26.145185185185184Ces méthodes minorent ou majorent le calcul d’aire selon les variations de $f$.
Une variante de ces deux méthodes consiste à prendre comme hauteur de chaque rectangle l’image du centre de l’intervalle d’où :

def methode_milieux(f,a,b,n):
h=(b-a)/n
A=0
for i in range(n):
A+=h*f(a+(i+0.5)*h)
return AUtilisation :
>>> methode_milieux(f,1,5,30)
25.327407407407406Au lieu de remplacer $f$ par une fonction constante sur l’intervalle $[x_i ; x_{i + 1}]$, on peut la remplacer par une fonction affine représentée par le segment qui joint les points $(x_i ; f(x_{i}))$ et $(x_{i + 1} ; f(x_{i + 1}))$ :

def trapezes(f,a,b,n):
h=(b-a)/n
A=0
for i in range(n) :
A+=h*(f(a+i*h)+f(a+i*h+h))/2
return AUtilisation :
>>> trapezes(f,1,5,30)
25.345185185185183Méthode de Monte-Carlo.
Cette méthode a été abordée en classe de première mais c’était limité au cas où $0\leq x\leq 1$ et $0\leq y\leq 1$, on va étendre la méthode au cas où $a\leq x\leq b$ et $0\leq y\leq M$ où M est un majorant de $f(x)$ sur $[a ; b]$.

On va tirer au hasard N points de coordonnées comprises entre a et b pour l’abscisse et entre 0 et M pour l’ordonnée, on compte le nombre de points S sous la courbe, l’aire sous la courbe est alors approchée par S/N*(b-a)*M.
from random import *
def f(x):
return x**2-3*x+5
def monte_carlo(f,a,b,M,n):
S = 0
for k in range(n):
(x,y) = (a+(b-a)*random(),M*random())
if y < f(x):
S += 1
return S/n*M*(b-a)Utilisation :
>>> monte_carlo(f,1,5,25,1000000)
25.343799999999998Probabilités
Simulation de la planche de Galton.

On considère une planche de Galton de $n$ étages. Un jeton qui tombe le long de cette planche peut être simuler par $n$ épreuves de Bernoulli dont les issues équprobables sont :
– « 0 » si jeton va à gauche
– « 1 » si le jeton va à droite
Si on repère les positions possibles du jeton par un nombre entier en partant de la droite, la positon finale du jeton correspond à la somme des valeurs des $n$ épreuves. Le script suivant permet d’effectuer cette simulation :
from random import choice
import matplotlib.pyplot as plt
def chute(n):
t=0
for k in range(n):
t=t+choice([0,1])
return t
def simule_planche(n_étages,n_lancés):
résultats=[0 for k in range(n_étages+1)]
for k in range(n_lancés):
c=chute(n_étages)
résultats[c]=résultats[c]+1
plt.bar(range(n_étages+1),s)
plt.show()Et le résultat est :

Une approche légèrement différente :
from matplotlib import pyplot
from random import random
def Galton(N,L):
positions=[]
for n in range(N):
pos=0
for l in range(L):
r=random()
if r>0.5:
pos+=1 # la bille va a droite
else:
pos-=1 # sinon a gauche
positions.append(pos)
pyplot.hist(positions,range = (-L, L), bins = 2*L, color = 'blue',edgecolor = 'grey')
pyplot.xlabel(str(N)+' billes lancées sur une planche avec '+str(L)+' lignes de clous.')
pyplot.ylabel('Effectifs')
pyplot.title('Planche de Galton')Utilisation :
>>>Galton(5000,13)

Simulation d’une marche aléatoire.
On pourra visualiser cette vidéo de la série 5 minutes Lebesgue pour soi ou avec ses élèves :
On simule avec le module Turtle une marche aléatoire de n pas ayant une même probabilité d´être effectués vers l’avant ou vers l’arrière. Pour que l’on voit la progression de Turtle le pas est réglé à 20 pixels et l’on change de couleur à chaque pas. Dans graphe2, on simule p déplacements de n pas dans 360/p directions. Dans graphe3, on change d’orientation à chaque pas. Dans graphe4, on simule la marche aléatoire unidimensionnelle symétrique.
from random import *
from turtle import *
def un_saut(x):
if random()<0.5:
return x-1
else:
return x+1
def position(n):
pos=0
for i in range(n):
pos+=un_saut(0)
return pos
def graphe1(n):
colormode(255)
goto(0,0)
for i in range(n):
forward(un_saut(0)*20) #Pas de 20 pixels
color((randrange(0,256), randrange(0,256),randrange(0,256)))
def graphe2(p,n):
for i in range(p):
goto(0,0)
setheading(0)
right(180*i/p)
graphe1(n)
def graphe3(n):
reset()
goto(0,0)
for i in range(n):
forward(un_saut(0)*20)
right(90*(-1)**randrange(0,2))
def graphe4(n):
reset()
goto(0,0)
setheading(0)
for i in range(n):
setheading(45*(-1)**randrange(0,2))
forward(20)Utilisation :
>>> graphe1(20)
>>> reset()
>>> graphe2(20,20)
>>> graphe3(20)Avec graphe1 :
![]()
Avec graphe2 :

Avec graphe3 :

Avec graphe4 :
