L’option « maths complémentaires » est la principale nouveauté dans les mathématiques mises en place avec la réforme du lycée. L’approche est thématique, les algorithmes très présents.
Cet article est long, complet et techniquement délicat : il rendra service à de très nombreux collègues.
Pourrions-nous demander aux utilisateurs de l’article de signaler les inévitables coquilles ou les anomalies qu’ils pourraient découvrir et qui nous auraient échappé...? Merci. (mathematice@sesamath.net)
Cet article peut être librement diffusé et son contenu réutilisé pour une utilisation non commerciale (contacter l’auteur pour une utilisation commerciale) suivant la licence CC-by-nc-sa
On peut lire dans le programme officiel de cette option :
Algorithmique et programmation
La démarche algorithmique est, depuis les origines, une composante essentielle de l’activité mathématique. Au collège, en mathématiques et en technologie, les élèves ont appris à écrire, mettre au point et exécuter un programme simple. Les classes de seconde et de première ont permis de consolider les acquis du collège (notion de variable, type de variables, affectation, instruction conditionnelle, boucle, notamment), d’introduire et d’utiliser la notion de fonction informatique et de liste. En algorithmique et programmation, le programme de mathématiques complémentaires reprend les programmes des classes de seconde et de première sans introduire de notion nouvelle, afin de consolider le travail des classes précédentes. Les algorithmes peuvent être écrits en langage naturel ou utiliser le langage Python. On utilise le symbole « ← » pour désigner l’affection dans un algorithme écrit en langage naturel. L’accent est mis sur la programmation modulaire qui permet de découper une tâche complexe en tâches plus simples. L’algorithmique trouve naturellement sa place dans toutes les parties du programme et aide à la compréhension et à la construction des notions mathématiques.

On va donc s’attacher à programmer les algorithmes listés dans le programme sans introduire de notions nouvelles :
Résolution d´équations du type $f(x) = k$ par balayage, par dichotomie, par la méthode de Newton.
Résolution d´équations par balayage
Cette méthode, classique, consiste, pour une fonction continue et monotone sur un intervalle $[a ; b]$ dans lequel on sait trouver la solution de $f(x) = k$, à calculer $f(x)$, pour $x$ allant de $a$ à $b$ avec un pas de $h$, après avoir vérifié la croissance ou la décroissance de la fonction. Si $f$ est croissante, « Tant Que » $f(x) < k$ est vérifiée (On utilisera pour cela un While.), on calcule $f(x)$. Dès que $f(x) > k$ on arrête l’algorithme. Si $f$est décroissante, « Tant Que » $f(x) > k$ est vérifiée, on calcule $f(x)$. Dès que $f(x) < k$ on arrête l’algorithme. On obtient un encadrement de longueur $h$ de la solution.
Il faut déterminer a et b, les bornes de l’intervalle dans lequel on va appliquer le balayage.
Fonction qui calcule cet encadrement, renvoyé dans un tuple, en fonction du nombre n de décimales souhaitées :
Cet algorithme détermine par balayage un encadrement de racine de 2 d’amplitude $10^{-n}$.
from math import cos
def f(x):
return cos(x)-x
def balayage(f,k,a,b,n):
fa,fb=f(a),f(b)
h=10**(-n)
x=a
if fa<fb:
while f(x)<k:
x=x+h
else:
while f(x)>k:
x=x+h
return (round(x-h,n),round(x,n))Utilisation : Compiler le fichier puis dans la console :
>> balayage(f,0,-1,2,6)
(0.739085, 0.739086)Le round permet ici de corriger quelques erreurs d’affichage des flottants [1].
Il est à noter que cet algorithme est très long à donner une réponse si n>=9.
On peut donc chercher à l’optimiser, par exemple en utilisant une boucle for qui va faire la même chose que le programme précédent mais pour h allant de 10-1 à 10-n en réduisant l’intervalle [a ; b] à chaque boucle.
C’est beaucoup plus rapide, jusqu’à n=16 où ça bogue, parce que les flottants (décimaux) ne sont affichés qu’avec 16 chiffres après la virgule.
def balayage2(f,k,a,b,n):
fa,fb=f(a),f(b)
for i in range(1,n+1):
h=10**(-i)
x=a
if fa<fb:
while f(x)<k:
x=x+h
else:
while f(x)>k:
x=x+h
a=x-h
return (round(x-h,n),round(x,n))Résolution d´équations par dichotomie
On va commencer par programmer l’algorithme classique de recherche de zéro d’une fonction sur un intervalle par dichotomie :
def zero(f,a,b,epsilon):
if f(a)*f(b)>0:
return "Les bornes de l'intervalle ne sont pas bien choisies."
while(abs(a-b)>epsilon):
m=(a+b)/2
if f(m)*f(a)>0:
a=m
else:
b=m
return mUtilisation :
>>> zero(f,-1,0,10**(-6))
"Les bornes de l'intervalle ne sont pas bien choisies."
>>> zero(f,-1,2,10**(-6))
0.7390849590301514Et l’on peut aisément résoudre l’équation $f(x) = k$ avec un petit aménagement :
def zero_k(f,a,b,epsilon,k):
def fk(x):
return f(x)-k
return zero(fk,a,b,epsilon)Utilisation :
>>> zero_k(f,-20,0,10**(-4),10)
-10.486984252929688Résolution d´équations du type $f(x) = k$ par la méthode de Newton.
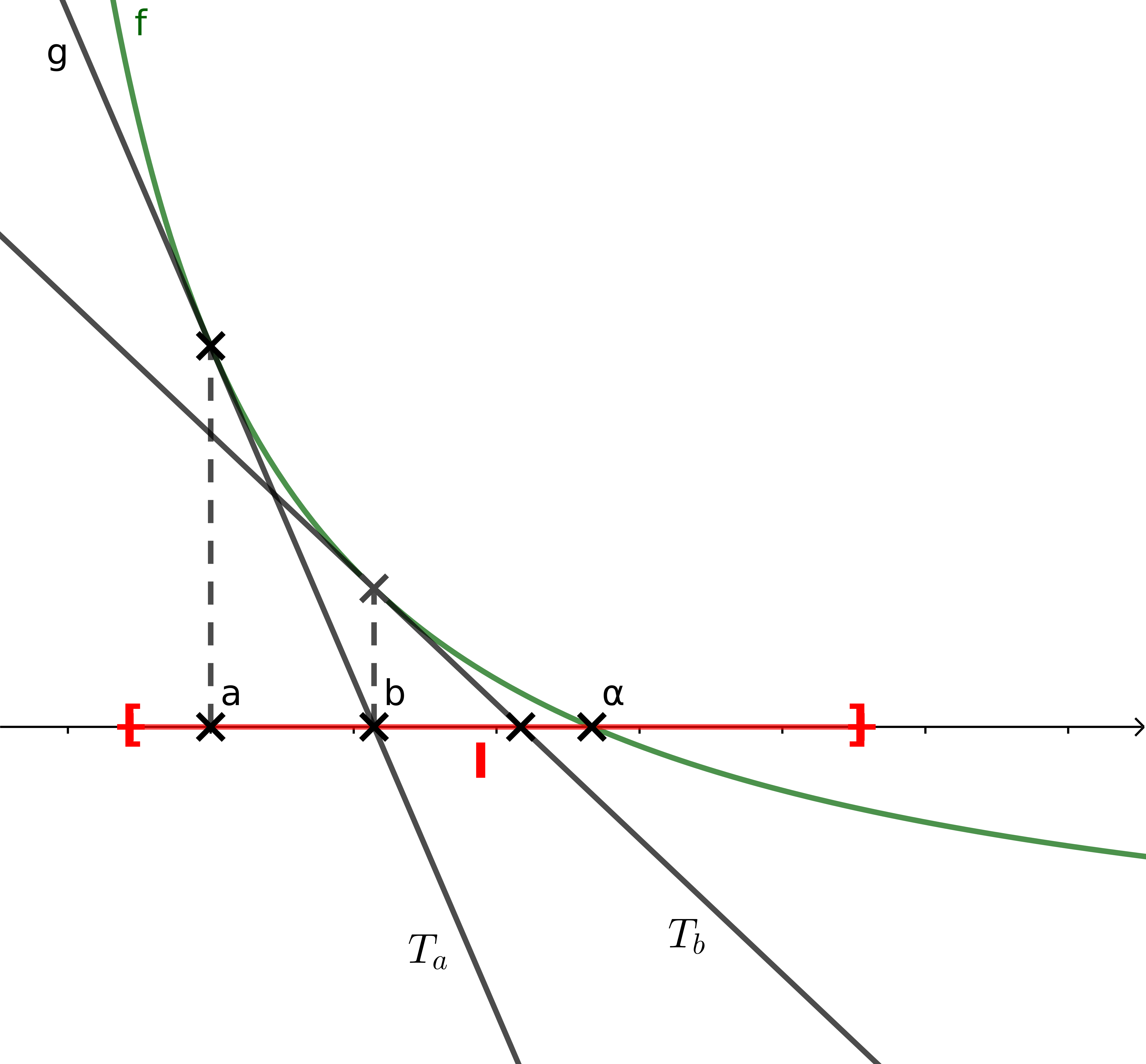
| Soit $f$ une fonction dérivable sur un intervalle $I$. L’équation $f (x) = 0$ admet une racine unique $\alpha$ sur cet intervalle $I$. Soit $a \in I$ une valeur approchée de $\alpha$. On va utiliser l’approximation affine $g$ de $f$ au point $a$. On aura donc $g(x) = f (a) + (x − a)f ′(a)$ (tangente $T_a$). La droite $T_a$ coupe l’axe des abscisses en $b = a −\frac{f(a)}{f’(a)}$. Sous certaines conditions, le nombre $b$ peut représenter une meilleure approximation de $\alpha$ que $a$. La méthode de Newton consiste à itérer le processus en repartant de $b$ et ainsi de suite. On proposera deux solutions : – si l’on sait dériver la fonction $f$.
|
Une lectrice avertie m’a fait une remarque qui m’amène à vous proposer une autre version :
def newton2(fonction,derivee,x0,e):
x = x0
while abs(fonction(x))>e:
d=derivee(x)
x = x-fonction(x)/d
return xUtilisation :
>>> newton2(f,derivee_f,2,1e-6)
0.7390851332198145
– si l’on doit se contenter d’un calcul approché de ce nombre dérivé en prenant comme approximation $f’(a) \approx \frac{f(a + h) - f(a)}{h}$ avec h suffisamment petit.
def newton3(f,x0,e,h):
x = x0
while abs(f(x))>e:
d = (f(x+h)-f(x))/h #on calcule une approximation du nombre dérivé en x
x = x-f(x)/d
return xUtilisation :
>>> newton3(f,2,1e-6,1e-5)
0.7390851332299205Recherche d’une valeur approchée de précision donnée (Dans le thème d’étude Calculs d’aires)
Méthode des rectangles, des trapèzes.
On note $(x_i)_{i \in\{0, ..., n\}}$ une subdivision de l’intervalle [a ; b] Avec $a=x_0 < x_1 < ... < x_n = b$ et pour tout $i \in \{0, ..., n\}, x_i=a+i{\frac {b-a}{n}}$.
Il y a plusieurs méthodes pour approcher l’aire sous la courbe d’une fonction continue à l’aide de rectangles, commençons par la méthode des rectangles à gauche :
On remplace $f$ par la valeur qu’elle prend sur le bord gauche de l’intervalle $[x_i ; x_{i + 1}]$ soit $f(x_i)$, l’aire est alors égale à $f(x_i)\times{\frac{b - a}{n}}$.

D’où l’algorithme suivant :
def f(x):
return x**2-3*x+5
def rectangles_gauche(f,a,b,n):
h=(b-a)/n
L=0
for i in range(n):
L+=f(a+i*h)
return L*hUtilisation :
>>> rectangles_gauche(f,1,5,30)
24.54518518518518Pour la méthode des rectangles à droite il suffit d’un tout petit changement :

def rectangles_droit(f,a,b,n):
h=(b-a)/n
L=0
for i in range(1,n+1):
L+=f(a+i*h)
return L*hUtilisation :
>>> rectangles_droit(f,1,5,30)
26.145185185185184Ces méthodes minorent ou majorent le calcul d’aire selon les variations de $f$.
Une variante de ces deux méthodes consiste à prendre comme hauteur de chaque rectangle l’image du centre de l’intervalle d’où :

def methode_milieux(f,a,b,n):
h=(b-a)/n
L=0
for i in range(n):
L+=f(a+(i+0.5)*h)
return L*hUtilisation :
>>> methode_milieux(f,1,5,30)
25.327407407407406Au lieu de remplacer $f$ par une fonction constante sur l’intervalle $[x_i ; x_{i + 1}]$, on peut la remplacer par une fonction affine représentée par le segment qui joint les points $(x_i ; f(x_{i}))$ et $(x_{i + 1} ; f(x_{i + 1}))$ :

def trapezes(f,a,b,n):
h=(b-a)/n
L=0
for i in range(n) :
L+=(f(a+i*h)+f(a+i*h+h))/2
return L*hUtilisation :
>>> trapezes(f,1,5,30)
25.345185185185183Méthode de Monte-Carlo pour un calcul d’aire.
Cette méthode a été abordée en classe de première mais c’était limité au cas où $0\leq x\leq 1$ et $0\leq y\leq 1$, on va étendre la méthode au cas où $a\leq x\leq b$ et $0\leq y\leq M$ où M est un majorant de $f(x)$ sur $[a ; b]$.

On va tirer au hasard N points de coordonnées comprises entre a et b pour l’abscisse et entre 0 et M pour l’ordonnée, on compte le nombre de points S sous la courbe, l’aire sous la courbe est alors approchée par S/N*(b-a)*M.
from random import *
def f(x):
return x**2-3*x+5
def monte_carlo(f,a,b,M,n):
S = 0
for k in range(n):
(x,y) = (uniform(a,b),uniform(0,M))
if y < f(x):
S += 1
return S/n*M*(b-a)Utilisation :
>>> monte_carlo(f,1,5,25,1000000)
25.343799999999998Chacune des méthodes précédentes peut être programmée en retournant directement la somme des éléments d’une liste plutôt que d’utiliser une boucle :
def rectangles_gauche2(f,a,b,n):
h=(b-a)/n
return sum([f(a+i*h) for i in range(n)])*h
def rectangles_droit2(f,a,b,n):
h=(b-a)/n
return sum([f(a+i*h) for i in range(1,n+1)])*h
def methode_milieux2(f,a,b,n):
h=(b-a)/n
return sum([f(a+(i+0.5)*h) for i in range(n)])*h
def trapezes2(f,a,b,n):
h=(b-a)/n
return sum([(f(a+i*h)+f(a+i*h+h))/2 for i in range(n)])*h
def monte_carlo2(f, a, b, n):
return sum([f(uniform(a, b)) for i in range(n)])*(b-a)/nPour cette dernière fonction, il n’a pas été possible de traduire la fonction monte_carlo() précédente à l’aide d’une liste, on a précédemment calculé une approximation de l’aire en procédant de la manière suivante :
– On a enfermé l’aire à calculer dans un rectangle de dimensions $(b - a)\times M$ ;
– On a lancé aléatoirement un grand nombre de points dans ce rectangle ;
– On a compté à chaque lancer ceux qui étaient sous la courbe, c’est-à-dire dans la surface que l’on veut calculer.
– On en a déduit par proportionnalité à une approximation de l’aire.
On ne peut pas simuler cela avec une liste mais on peut utiliser une variante de la méthode de Monte-Carlo (L’algorithme de la moyenne ou l’algorithme de l’espérance ou encore ici) :
– On tire aléatoirement et uniformément un grand nombre de nombres aléatoires x entre a et b ;
– On prend, à chaque tirage, comme approximation de l’aire, l’aire du rectangle de largeur b - a et de hauteur f(x) ;
– On calcule la moyenne des aires obtenues.
Il s’agit de l’algorithme monte_carlo2() ci-dessus.
Recherche de valeurs approchées de constantes mathématiques, par exemple π, ln2,√2
Valeur approchée de π
Nous avons déjà approximé π en classe de première avec la méthode d’Archimède et la méthode de Monte Carlo, nous utiliserons en Terminale la formule de Bellard :
$\displaystyle \pi ={\frac {1}{2^{6}}}\sum _{n=0}^{\infty }{\frac {(-1)^{n}}{2^{10n}}}\left(-{\frac {2^{5}}{4n+1}}-{\frac {1}{4n+3}}+{\frac {2^{8}}{10n+1}}-{\frac {2^{6}}{10n+3}}-{\frac {2^{2}}{10n+5}}-{\frac {2^{2}}{10n+7}}+{\frac {1}{10n+9}}\right)$
def bellard(n):
pi=0
for i in range(n+1):
pi+=(-2**5/(4*i+1)-1/(4*i+3)+2**8/(10*i+1)-2**6/(10*i+3)-2**2/(10*i+5)-2**2/(10*i+7)+1/(10*i+9)) *(-1)**i/(2**6*2**(10*i))
return piUtilisation :
>>> bellard(3)
3.1415926535897545
>>> bellard(4)
3.1415926535897922A noter que Python ne peut faire mieux que bellard(4) qui n’est pas une bonne approximation puisque les 3 dernières décimales sont erronées. En utilisant le module Decimal, on obtient deux décimales exactes de plus, pas plus ...
Valeur approchée de $\ln{2}$
En écrivant $\ln(2)=\int_{1}^{2} \frac{1}{t}dt$ et en subdivisant de manière de plus en plus fine l’intervalle [1 ; 2] pour approcher cette intégrale par une somme de Riemann.
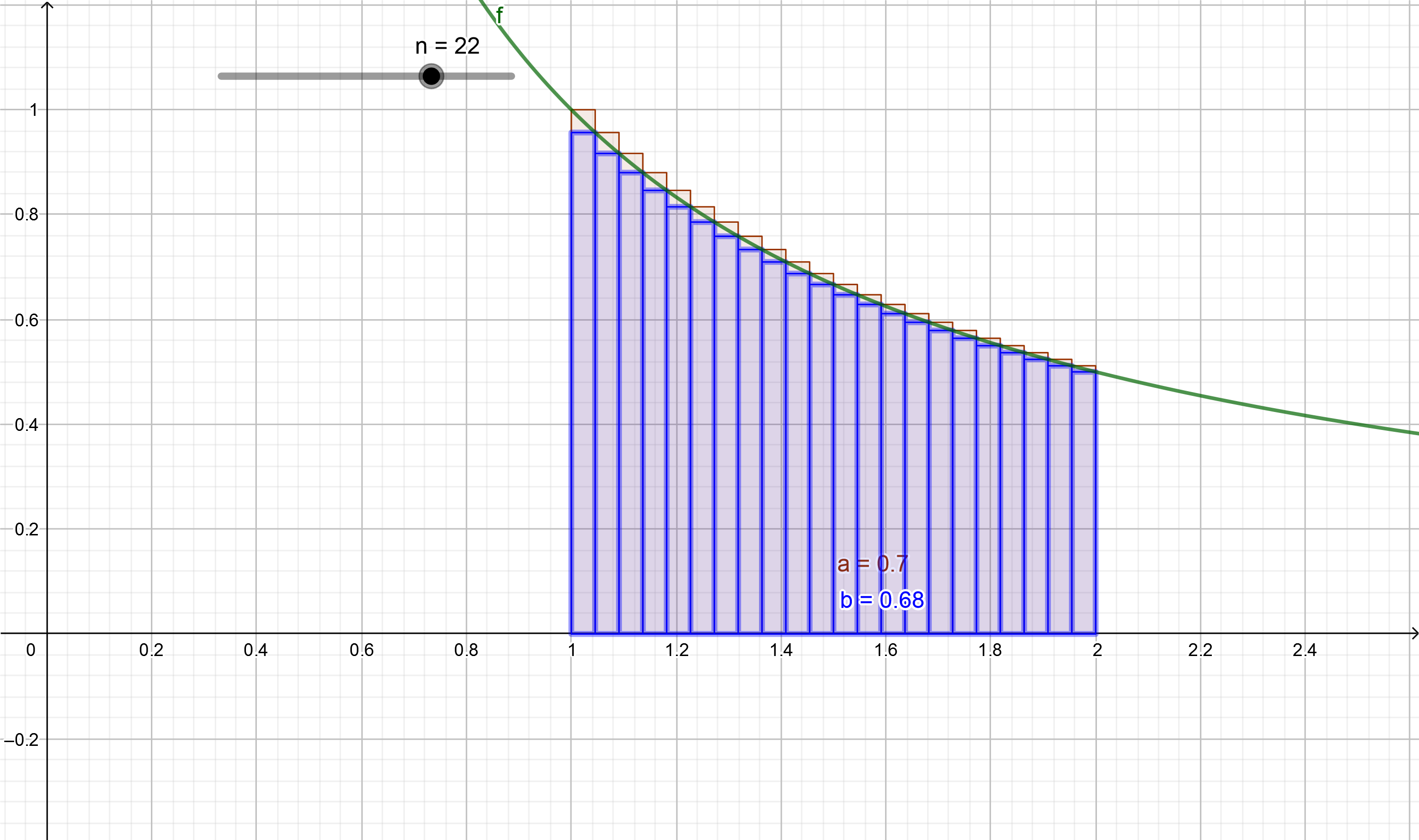
Nous verrons cela plus loin dans l’article.
Nous allons donc calculer $ln(2)$ au moyen de la série harmonique alternée : ${\displaystyle \ln(2) =\lim _{n\to \infty }\left(\sum _{k=1}^{n}{\frac {(-1)^{k + 1}}{k}}\right)}$
def ln2(n):
ln2=0
for i in range(1,n+1):
ln2+=(-1)**(i+1)/i
return ln2Utilisation :
>>> ln2(1000)
0.6926474305598223
>>> ln2(10000)
0.6930971830599583Cela converge très lentement puisque $\ln(2) \approx 0.69314718056$ ...
Valeur approchée de $\sqrt{2}$
On doit à Théon de Smyrne ces deux suites $(p_n)$ et $(q_n)$ définies par récurrence :
$p_{n + 1} = p_n + 2q_n, p_0 = 1$ ;
$q_{n + 1} = p_n + q_n, q_0 = 1$.
Ces suites sont à valeur entière strictement positive, donc strictement croissantes par récurrence, et vérifient :
$p_n² − 2q_n² = (−1)^n(p_0² − 2q_0²)$ de sorte que $\frac{p_n}{q_n}$ tend vers $\sqrt{2}$.
def racine2(n):
p,q=1,1
for i in range(n):
p,q=p+2*q,p+q
return p/qUtilisation :
>>> racine2(10)
1.4142135516460548
>>> racine2(100)
1.4142135623730951Méthode d’Euler
Soit $f$ une fonction dérivable sur $]0 ; +\infty[$ et vérifiant $f(1) = 0$ et pour tout $x \in ]0 ; +\infty[, f’(x) = \frac{1}{x}$. Utilisons la méthode d’Euler pour tracer une courbe approchée sur l’intervalle [1 ; 3] de cette fonction f.
La méthode d’Euler consiste à construire une suite de points $(x_n ; y_n)$ telle que $y_n$ soit proche de $f(x_n)$. Ainsi le nuage de points $(x_n ; y_n)$ formera une approximation de la courbe représentative de la fonction $f$.
La suite $(x_n)$ est une suite arithmétique de raison $h>0$ et de premier terme 1, $h$ est appelé le pas. On a donc $x_n = 1 + nh$ et $x_{n+1}=x_n + h$.
La suite $(y_n)$ est définie par $y_0 = f(x_0) = f(1) = 0$ et pour tout $n \in \mathbf{N}, y_{n+1}=y_n+hf’(x_n)$. C’est-à-dire que l’on se sert de l’approximation affine de la fonction par ses tangentes successives.
On a $y_{n+1}=y_n+\frac{h}{x_n}$.
D’où le script suivant :
import matplotlib.pyplot as plt
def Euler(x_f,n) :
x=1
y=0
h=x_f/n
abscisse=[1]
ordonnee=[0]
for i in range(n) :
y=y+h/x
x=x+h
abscisse.append(x)
ordonnee.append(y)
plt.plot(abscisse,ordonnee,"r")
plt.show()Utilisation, pour un nuage de n=100 points pour x allant de 1 à x_f=3 :
>>> Euler(3,100)Ce qui donne le graphique suivant :

Et si l’on veut comparer avec le « vrai » graphe de la fonction logarithme neperien :
import matplotlib.pyplot as plt
from math import log
def Euler(x_f,n) :
x=1
y=0
h=x_f/n
abscisse=[1]
ordonnee=[0]
ln=[0]
for i in range(n) :
y=y+h/x
x=x+h
abscisse.append(x)
ordonnee.append(y)
ln.append(ln(x))
plt.plot(abscisse,ordonnee,"r")
plt.plot(abscisse,ln,"b")
plt.show()

Simulation d’une variable aléatoire de loi géométrique à partir du schéma de Bernoulli.
Définition : Soit $0 < p < 1$. On dit qu’une variable $X$ suit une loi géométrique de paramètre $p$, notée $G(p)$ si
a) $X$ est à valeurs dans $\mathbb{N}^{{}∗{}}$ ;
b) $∀k≥1, P(N=k) = (1−p)^{k−1}p$.
La variable aléatoire qui suit une loi géométrique de paramètre $p$ peut être assimilée au temps d’attente du premier succès d’un schéma de Bernoulli :
from random import random
def attente_succes(p):
temps_attente=1
alea=random()
while alea>p:
alea=random()
temps_attente+=1
return temps_attenteUtilisation :
>>> attente_succes(0.2)
3
>>> attente_succes(0.2)
10
>>> attente_succes(0.2)
1
>>> attente_succes(0.2)
4
>>> attente_succes(0.2)
23On peut alors simuler un grand nombre de fois l’expérience et représenter graphiquement le résultat :
from random import random
import matplotlib.pyplot as pyplot
def attente_succes(p):
temps_attente=1
alea=random()
while alea>p:
alea=random()
temps_attente+=1
return temps_attente
def simulation(p,N):
liste_nbtirages=[0]*30
for i in range(N):
t=attente_succes(p)
if t<=30:
liste_nbtirages[t-1]+=1
pyplot.xlabel("Nombde de tentatives avant le succès")
pyplot.ylabel("Effectifs")
pyplot.bar(range(1,31),liste_nbtirages,width=0.5,color="blue")
pyplot.show()Utilisation :
>>> simulation(0.2,100000)

On peut aussi afficher le résultat théorique :
def loi_geom(p,k):
K=[k for k in range(1,k+1)]
P=[p*(1-p)**(k-1) for k in range(1,k+1)]
pyplot.xlabel("Nombre de tentatives avant le succès")
pyplot.ylabel("Probabilité")
pyplot.bar(K,P)
pyplot.show()Utilisation :
>>> loi_geom(0.2,30)

Simulation d’une loi exponentielle à partir d’une loi uniforme.
On peut simuler la loi uniforme sur l’intervalle [a ; b] à l’aide de la fonction random() du module random :
from random import random
def uniforme(a,b):
return(a+(b-a)*random())En effet random() renvoie un nombre aléatoire de l’intervalle [0 ; 1[ (La suite de nombres générée “ressemble” à une suite de variables aléatoires uniformes et indépendantes.), donc (b-a)*random() renvoie un nombre aléatoire de l’intervalle [0 ; b-a[ et a+(b-a)*random() renvoie un nombre aléatoire de l’intervalle [a ; b[ .
La fonction densité de probabilité de cette loi uniforme sur [a ; b] est une fonction constante par morceaux :
def densuni(x,a,b):
#densité sur [a,b]
if (a<=x and x<=b):
return(1/(b-a))
else:
return(0)Et si l’on veut sa représentation graphique :
import numpy as np
import matplotlib.pyplot as plt
from random import random
def uniforme(a,b):
return(a+(b-a)*random())
def densuni(x,a,b):
#densité sur [a,b]
if (a<=x and x<=b):
return(1/(b-a))
else:
return(0)
def graph_uniforme(a,b):
abs=np.linspace(a-(b-a),b+(b-a),200)
y=[densuni(x,a,b) for x in abs]
plt.grid()
plt.plot(abs,y)
plt.show()Utilisation :
>>>graph_uniforme(-5,10)

On peut aussi s’intéresser à la fonction de répartition :
def repartuni(x,a,b):
#fonction de répartition sur [a,b]
if x<a:
return(0)
elif (a<=x and x<=b):
return((x-a)/(b-a))
else:
return(1)
def graph_repartuniforme(a,b):
abs=np.linspace(a-(b-a),b+(b-a),200)
y=[repartuni(x,a,b) for x in abs]
plt.grid()
plt.plot(abs,y)
plt.show()Utilisation :
>>>graph_repartuniforme(-5,10)

Pour la loi exponentielle de paramètre λ, on a $F(x) = 1−e^{−λx}$ pour $x \geqslant 0$ et $F(x) = 0$ si $x \lt 0$. Sur $\mathbb{R}+$ , la fonction F(x) est continue et strictement croissante, on a l’équivalence :
$u = 1−e^{−λx} \Leftrightarrow 1 - u = e^{−λx} \Leftrightarrow ln(1 - u) = −λx \Leftrightarrow x = F^{−1}(u) =−\frac{1 }{λ}ln(1−u)$.
On peut donc simuler X à partir de U puisque $F^{−1}(U)$ suit la même loi que X.
On peut alors écrire une fonction Expo qui prend en argument un réel a>0 et renvoie une réalisation d’une variable aléatoire qui suit la loi Exponentielle de paramètre a :
from math import log
from random import *
def Expo(a):
return -1/a*log(1-random())Utilisation :
>>>Expo(2)
>>>0.5242804058215232
>>>Expo(0.2)
>>>3.2637966061217183On peut alors utiliser une fonction qui va procéder à un nombre n de tirages aléatoires :
def tirages(n,a):
L=[]
for i in range(n):
L.append(Expo(a))
return LUtilisation :
>>>tirages(10,0.3)
>>>[1.4373901275636258,
4.961359207330598,
1.5097403973808872,
5.805058647163496,
9.818932947901471,
11.037823931384885,
1.3647856789399562,
3.4588250161094725,
2.9218462025078207,
4.015415133657791]On peut alors passer à la représentation graphique en utilisant la commande hist [2] du module matplotlib :
def graphe(n,a):
L=tirages(n,a)
maxL=int(max(L))
hist(L , bins = 100, range=(0,maxL), normed = True)

On peut alors compléter le graphique avec la densité théorique $f(x)=ae^{−a x}$.
from matplotlib.pyplot import *
from random import *
from math import log,exp
def Expo(a):
return -1/a*log(1-random())
def tirages(n,a):
L=[]
for i in range(n):
L.append(Expo(a))
return L
def graphe(n,a):
L=tirages(n,a)
maxL=int(max(L))
hist(L , bins = 100, range=(0,maxL), normed = True)
x = [float(i)/100 for i in range(100*maxL)]
f = [a*exp(-a*t) for t in x]
plot(x,f)
graphe(10000,0.5)

Enfin l’on peut s’intéresser à la fonction de répartition, que l’on peut simuler avec un histogramme des effectifs cumulés croissants de densité 1 :
def repartition(n,a):
L=tirages(n,a)
maxL=int(max(L))
hist(L , bins = 100, range=(0,maxL), density = True,cumulative=True)
show()Utilisation :
>>> repartition(10000,0.4)

On peut alors compléter le graphique avec la fonction de répartition théorique $F(x)=1−e^{−ax}$.
Il y a un paramètre dans la commande hist de matplotlib : cumulative=True qui permet d’avoir les Effectifs Cumulés Croissants et avec density=True on a les Fréquences Cumulées Croissantes, donc la fonction de répartition.
def repartition(n,a):
L=tirages(n,a)
maxL=int(max(L))
hist(L , bins = 100, range=(0,maxL), density = True,cumulative=True)
x = [float(i)/100 for i in range(100*maxL)]
f = [1-exp(-a*t) for t in x]
plot(x,f)
show()Utilisation :
>>> repartition(50000,3)

Demi-vie d’un échantillon de grande taille d’atomes radioactifs.
Décroissance radioactive :
Pour simuler le caractère aléatoire de la désintégration d’un noyau individuel, on peut simuler à l’aide d’un programme Python, si l’on connait la probabilité p de désintégration d’un noyau, on utilise une variable aléatoire qui, si elle est inférieure à p élimine le noyau. Pour travailler sur un échantillon, on fait cela pour n noyaux.
from random import *
def compte_noyaux_restants(n,p):
N=n
for i in range(n):
if random() < p :
N=N-1
return NUtilisation :
>>> compte_noyaux_restants(10000,0.02)
9821On peut alors réitérer cela jusqu’á ce qu’il n’y ait plus de noyaux (En fait on s’arrêtera lorsqu’il en reste moins de 1%) :
def Liste_nb_noyaux_restants(n,p):
L=[]
N=n
while n>0.01*N:
L.append(n)
n=compte_noyaux_restants(n,p)
return LUtilisation :
>>> Liste_nb_noyaux_restants(10000,0.02)
[10000, 9802, 9606, 9417, 9240, 9069, 8886, ...., 111, 108, 106, 102, 102]Et la représentation graphique :
import matplotlib. pyplot as plt
def simule_desintegration(n,p):
L=Liste_nb_noyaux_restants(n,p)
plt.plot(range(len(L)),L, linestyle ="none",marker=".")
plt.show()
simule_desintegration(10000,0.03)

Demi-vie :
La demi-vie d’un noyau radioactif, également appelée période radioactive, est la durée nécessaire pour que la moitié des noyaux initialement présents dans un échantillon macroscopique se soit désintégrée. En raison de l’absence de vieillissement, cette demi-vie, caractéristique du noyau considéré, est indépendante de l’instant initial. La demi-vie est, généralement, notée $T_{\frac{1}{2}}$.
def demi_vie(N,p):
n=N
i=0
while n>N/2:
i+=1
n=compte_noyaux_restants(n,p)
return iUtilisation :
>>> demi_vie(10000,0.03)
23
>>> demi_vie(1000,0.02)
36
>>> demi_vie(10000,0.02)
35Datation au carbone 14 :
Les organismes vivants contiennent naturellement du carbone 14 ($^{14}C$) provenant de l’interaction des rayons cosmiques avec le carbone présent dans l’atmosphère. La proportion de $^{14}C$ par rapport au $^{12}C$ présent dans un organisme vivant est constante, égale à $1,3\times 10^{-12}$. À la mort d’un organisme, les échanges avec l’atmosphère cessent. Le carbone 14 qu’il contient se désintègre à raison de 12 pour 1000 tous les 100 ans, alors que le $^{12}C$ n’évolue pas.
La demi-vie du $^{14}C$ est d’environ 5800 ans (5 730 ± 40 ans selon Wikipedia) :
>>> demi_vie(100000,12/1000)
58
>>> demi_vie(100000,12/100000)
5794La méthode la plus courante de datation consiste à déterminer la concentration $C_t$ de radiocarbone (c’est-à-dire le rapport $\frac{^{14}C}C_{total}$) d’un échantillon à l’instant $t$ de mesure ; l’âge de l’échantillon est alors donné par la formule : $t − t_0 = \frac{1}{λ}\times ln \frac{C_0}{C_t}$ où ${C}_{0}$ est la concentration de radiocarbone de l’échantillon à l’instant $t_0$ de la mort de l’organisme d’où provient l’échantillon $\left(C_0 \approx 1.3\times 10^{− 12}\right)$ et λ la constante radioactive du carbone 14$\left(\lambda = \frac {\ln 2}{t_{\frac {1}{2}}} \approx 1,210\cdot 10^{-4} {an} ^{-1}\right)$.
D’où l’algorithme :
from math import log
def datation_C14(p):
C0=1.3*10**(-12)
lamb=1.21*10**(-4)
return round(1/lamb*log(C0/p))Des archéologues ont trouvé des fragments d’os dans lesquels la proportion de carbone 14 par rapport au carbone 12 est égale à $7\times 10^{-13}$. Estimer l’âge de ces fragments d’os.
>>> datation_C14(7*10**(-13))
5116On a découvert dans une grotte en Dordogne un foyer contenant du charbon de bois. À quantité égale, un morceau de bois actuel contient 1,5 fois plus de $^{14}C$ que le charbon de bois prélevé dans la grotte. Estimer une datation de l’occupation de la grotte.
>>> datation_C14(1.3*10**(-12)/1.5)
3351Lorsque la teneur en carbone 14 d’un organisme devient inférieure à 0,3 % de sa valeur initiale, on ne peut plus dater précisément à l’aide du carbone 14. Déterminer l’âge à partir duquel un organisme ne peut plus être daté au carbone 14.
>>> datation_C14(0.3/100*1.3*10**(-12))
48009Sur des exemples, résolution approchée d’une équation différentielle par la méthode d’Euler.
Résolution par la méthode d’Euler de $y’ = y$, et de $y’ = ay + b$.
En mathématiques, la méthode d’Euler est une procédure numérique pour résoudre par approximation des équations différentielles du premier ordre avec une condition initiale. C’est la plus simple des méthodes de résolution numérique des équations différentielles.
Pour h proche de 0, on a $y(a+h) \approx y(a) + h y’(a)$ .Nous allons utiliser cette approximation affine pour construire pas à pas une fonction vérifiant une équation différentielle du premier ordre et passant par un point donné $(x_0 ; y_0)$.
Soit l’équation différentielle définie par $y’=y$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $y_0$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + hy_0 = y_0(1 + h)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
def Euler(x0,xf,y0,n):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y*(1+h)
abscisse.append(x)
ordonnee.append(y)
return ordonneeUtilisation :
>>> Euler(0,3,1,30)
[1, 1.1, 1.2100000000000002, 1.3310000000000004, 1.4641000000000006, 1.6105100000000008, 1.771561000000001,
1.9487171000000014, 2.1435888100000016, 2.357947691000002, 2.5937424601000023, 2.853116706110003,
3.1384283767210035, 3.4522712143931042, 3.797498335832415, 4.177248169415656, 4.594972986357222,
5.054470284992944, 5.559917313492239, 6.115909044841463, 6.72749994932561, 7.400249944258172, 8.140274938683989,
8.954302432552389, 9.849732675807628, 10.834705943388391, 11.91817653772723, 13.109994191499954,
14.420993610649951, 15.863092971714948, 17.449402268886445]Le graphique ci-dessous est réalisé avec les données ci-dessus et les valeurs exactes.

Soit l’équation différentielle définie par $y’= ay + b$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $ay_0 + b$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + h (ay_0 + b)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
def Euler(x0,xf,y0,n,a,b):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y+h*(a*y+b)
abscisse.append(x)
ordonnee.append(y)
return ordonneeUtilisation :
>>> Euler(0,3,2,30,-0.5,0)
[2, 1.9, 1.805, 1.71475, 1.6290125, 1.547561875, 1.47018378125, 1.3966745921875001, 1.3268408625781252,
1.2604988194492188, 1.1974738784767578, 1.13760018455292, 1.080720175325274, 1.0266841665590103,
0.9753499582310597, 0.9265824603195068, 0.8802533373035314, 0.8362406704383548, 0.7944286369164371,
0.7547072050706152, 0.7169718448170844, 0.6811232525762302, 0.6470670899474187, 0.6147137354500477,
0.5839780486775453, 0.5547791462436681, 0.5270401889314846, 0.5006881794849104, 0.4756537705106649,
0.45187108198513165, 0.4292775278858751]

Et l’on peut généraliser le processus :
Soit l’équation différentielle définie par $y’=f(x,y)$ et les conditions initiales $(x_0 ; y_0)$. En $(x_0 ; y_0)$, on connaît la pente de la tangente à partir de l’équation différentielle, $f(x_0 ; y_0)$. On assimile alors sur l’intervalle $[x_0 ; x_0 + h]$ la fonction à sa tangente. On détermine alors le point $(x_1 ; y_1)$ avec $x_1 = x_0 + h$ et $y_1 = y_0 + hf(x_0,y_0)$. On recommence le même raisonnement avec le point $(x_1 ; y_1)$. On poursuit en construisant la suite de points $(x_n ; y_n)$ et en assimilant la courbe à une application affine par morceaux.
La fonction « Euler » ci-dessous prend comme dernier argument une fonction de deux variables :
def Euler(x0,xf,y0,n,f):
x=x0
y=y0
h=(xf-x0)/float(n)
abscisse=[x0]
ordonnee=[y0]
for i in range(n):
x=x+h
y=y+h*f(x,y)
abscisse.append(x)
ordonnee.append(y)
return ordonneeOn peut tester la fonction précédente avec f définie par f(x,y)=-0.5y :
>>> def f(x,y):
... return -0.5*y
...
>>> Euler(0,3,2,30,f)
[2, 1.9, 1.805, 1.71475, 1.6290125, 1.547561875, 1.47018378125, 1.3966745921875001, 1.3268408625781252,
1.2604988194492188, 1.1974738784767578, 1.13760018455292, 1.080720175325274, 1.0266841665590103,
0.9753499582310597, 0.9265824603195068, 0.8802533373035314, 0.8362406704383548, 0.7944286369164371,
0.7547072050706152, 0.7169718448170844, 0.6811232525762302, 0.6470670899474187, 0.6147137354500477,
0.5839780486775453, 0.5547791462436681, 0.5270401889314846, 0.5006881794849104, 0.4756537705106649,
0.45187108198513165, 0.4292775278858751]Ce qui donne bien le résultat précédent comme on s’y attendait.
Simulation du comportement de la somme de n variables aléatoires indépendantes et de même loi.
Soit n un nombre entier naturel supérieur ou egal à 2. $X_1, X_2, ... , X_n$ sont des variables aléatoires qui suivent la loi uniforme sur [0 ; 1].
Soit Y la variable aléatoire qui prend toutes les valeurs $x_1 + x_2 + ... + x-n$ correspondant à la somme des valeurs prises par $X_1, X_2, ... , X_n$. Y est donc à valeur dans [0 ; n], quelle est la loi suivie par Y ?
On peut utiliser une fonction Python pour simuler cette variable aléatoire :
from random import *
def somme(N,n):
L=[0]*n
for i in range(N):
x=0
for k in range(n):
x=x+random()
x=int(x)
L[x]+=1
for r in range(n):
L[r]=L[r]/1000
return LAprès avoir sommé les n valeurs, on les arrondit afin d’obtenir des effectifs pour n valeurs discrètes. On peut ensuite tracer l’allure de la fonction de répartition de Y :
from random import *
import matplotlib.pyplot as pyplot
def somme(N,n):
L=[0]*n
for i in range(N):
x=0
for k in range(n):
x=x+random()
x=round(x)
L[x]+=1
for r in range(n):
L[r]=L[r]/1000
A=[k for k in range (n)]
pyplot.bar(A,L,width=0.5,color="blue")
pyplot.show()
return LUtilisation :
>>> somme(1000,16)
[0, 0, 0, 0, 3, 43, 142, 349, 279, 147, 35, 2, 0, 0, 0, 0]
[0.0, 0.0, 0.0, 0.0, 0.003, 0.043, 0.142, 0.349, 0.279, 0.147, 0.035, 0.002, 0.0, 0.0, 0.0, 0.0]

Version 2 en utilisant la fonction hist de matplotlib :
from random import *
import matplotlib.pyplot as pyplot
def somme2(N,n):
L=[]
for i in range(N):
x=0
for k in range(n):
x=x+random()
L.append(x)
pyplot.hist(L,bins=100,range=(1,n+1))
pyplot.show()Utyilisation :
>>> somme2(1000,16)
