L’article qui suit est issu des travaux de l’atelier scientifique du Lycée Parc de Vilgénis, à Massy. Les lycéens de l’atelier [1], sous la direction de leur professeur Jacques Taillet, ont obtenu le prix CGénial 2021 pour le projet Pollubike. L’article a été rédigé en interaction avec Bernard Ycart pour la partie statistiques.
I. Introduction
1. Origine du projet
Le projet Pollubike est né de la volonté d’obtenir des informations sur la qualité de l’air en ville afin de connaître les itinéraires « les plus sains » pour piétons et cyclistes.
Fin 2018, Lab Innovation Ericsson France nous a contactés pour entamer une collaboration afin de développer le « Pollubike », un boîtier autonome fixé sur des vélos en libre circulation dans la ville de Massy.
2. Fonctionnement
Le Pollubike est à placer sur un vélo, ou une poussette par exemple. Il embarque un capteur de particules grossières permettant de mesurer la concentration de certaines particules en suspension :
- les particules au dessus de 1 μm que nous appellerons « PM 10 » par abus de langage ;
- les particules au dessus de 2.5 μm que nous appellerons « PM 25 » pour les mêmes
raisons.
La valeur obtenue est mesurée en ppm : « partie par million ». Le Pollubike transmet ensuite sa position, ainsi que les mesures liées à cette position, à une base de données, à l’aide de sa carte GPS et 4G. On peut ensuite consulter ces valeurs de pollution sur une carte libre de droit , OpenStreetMap, sous la forme de pastilles de couleurs.
3. Pollubike en quelques chiffres

4. Les objectifs des données
Ce grand nombre de données va nous permettre d’améliorer notre Pollubike, comme en trouvant des défauts et imperfections dans son algorithme ou sa structure. A venir, il sera peut être envisageable d’aller jusqu’à remettre en cause l’organisation des rues de la ville, la position de certains bâtiments. Si un jour le nombre de Pollubike est très élevé, il sera également possible d’user de ces données pour alimenter un réseau de neurones artificiel afin de prédire la pollution.
II. Analyse des données
1. Protocole
On allume le Pollubike, on roule (ou on marche) avec ce dernier, puis, lorsque l’on arrête les tests, on éteint le Pollubike. Une fois rentrés, on importe les mesures en .csv pour ensuite les analyser à l’aide de différents tests.
Au départ, nous avons réalisé les différents tests statistiques « à la main » à l’aide de notre tableur-grapheur. Toutefois nous nous sommes rapidement tournés vers le langage de programmation R. Celui-ci nous a permis de réaliser nos tests plus rigoureusement et d’en découvrir de nouveaux.
On définit le risque α à 5% soit α = 0.05 pour nos différents tests.
2. Irrégularités et différences entre les mesures enregistrées et envoyées
— Problèmes constatés
Les premières analyses montrent que notre prototype n’envoie pas les données de façon régulière. Mais alors, Pollubike envoie-t-il des données lorsqu’il est allumé ? Est-ce que le nombre de mesures envoyées est variable ?
Nous avons regroupé plusieurs informations sur les données envoyées et les mesures faites sur les graphiques ci-dessous.
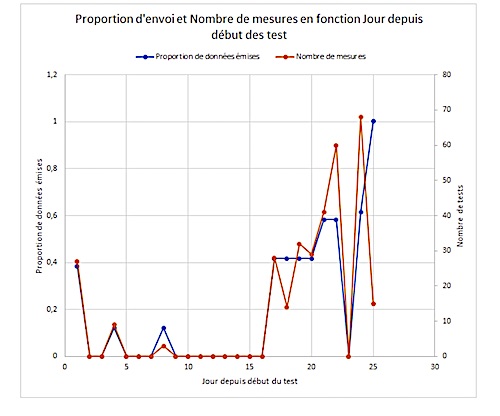
La courbe bleue représente le rapport entre le nombre de données (en orange) et un nombre de référence qui est censé être le maximum de données que peut envoyer notre Pollubike. Par exemple, pour le jour 24, la proportion de mesures envoyées a été de 50%. Le nombre de données récoltées a été de 70. On peut donc conclure que le nombre maximal de mesures qu’aurait pu envoyer Pollubike aurait été 140. On observe donc que le nombre de données envoyées par le Pollubike est très inférieur à celui attendu. En d’autres termes, notre boîtier n’envoie pas systématiquement des données lorsqu’on l’allume.
— Ajout du condensateur
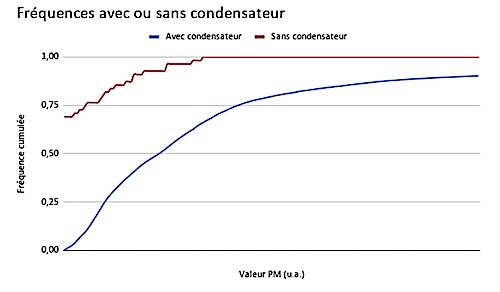
Pour pallier ce manque de fiabilité nous avons ajouté un condensateur au niveau du module de charge afin de l’isoler. Cela nous permet d’éviter toute variation brusque de tension et donc d’empêcher toute modification de données.
Il nous faut donc vérifier que cet apport est réellement efficace.
Après la réalisation de notre test, nous avons conclu que les deux fonctions de répartition n’étaient pas similaires, avec un risque de se tromper bien inférieur à 5%. L’ajout du condensateur a donc un impact significatif sur les données mesurées, de plus on voit la proportion de données non envoyées (représentées par la valeur 0) passer de 70% à près de 0% après ajout du condensateur.
Ce dernier est donc bien utile pour notre Pollubike.
3. Sens de l’ouverture
— Démarche de vérification
| Des discussions entre élèves et professeurs nous amènent à nous demander si le sens de l’ouverture du Pollubike possède une influence sur le nombre de données récoltées. En effet, on peut dire qu’il est naturel de placer l’ouverture face à l’entrée d’air afin de permettre un meilleur renouvellement de l’air au sein du boîtier. Toutefois, d’autres pensent qu’en faisant cela, un mouvement d’air pourrait venir fausser les résultats. Il serait alors préférable de garder l’ouverture du côté interne. |
 |
— Tests
On réalise les tests à l’aide du langage de programmation statistique, R. On appelle « Avant » la série de données mesurées en orientant le Pollubike vers l’avant. Et inversement « Arrière » désigne la série de données des mesures faites dans l’autre sens. Les deux séries comportent toutes les deux 457 mesures.
a. Test de Kolmogorov-Smirnov
On part de l’hypothèse initiale H0 : « Avant et Arrière suivent la même loi ».
Notre hypothèse alternative sera donc simplement H1 : « Avant et Arrière ne suivent pas la même loi ».
La p-valeur est p = 0.0142 < 0.05, on peut alors rejeter H0 et accepter H1.
Les valeurs des deux populations ne sont donc pas similaires en termes de distribution.
Donc le sens a une influence sur les données mesurées.
b. Test T de Student
D’un côté, H0 désigne “« Avant et Arrière ont des moyennes statistiquement égales”
D’un autre côté, H1 se caractérise par « Avant et Arrière ont des moyennes statistiquement différentes ».
On obtient une p-valeur de 0.1796. On a donc aucune présomption contre l’hypothèse nulle : les moyennes de nos deux séries sont relativement égales.
Cela vient étayer l’idée selon laquelle le sens de l’ouverture n’a pas d’impact significatif. Il va donc falloir faire un troisième test pour répondre.
c. Test de Mann-Whitney
Pour ce test non paramétrique l’hypothèse nulle est « la probabilité qu’une valeur de la série Avant soit supérieure à une autre de la série Arrière est de 50%.
Au contraire, H1 sera que : « cette probabilité est significativement différente de 50% ».
On obtient une p-valeur de 0.3352. On peut donc rejeter l’hypothèse alternative et dire que les données proviennent d’une même population. Ainsi le sens du Pollubike n’a pas d’importance sur les données.
— Graphique et conclusion
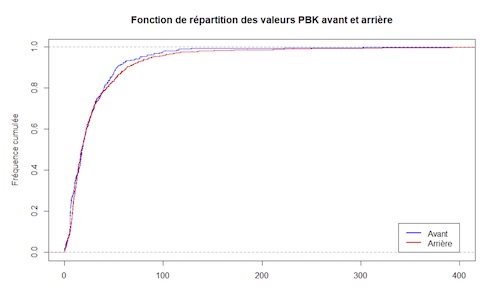
L’observation du graphique nous conforte dans l’idée que le sens du Pollubike a peu d’importance sur la mesure de nos données, bien que le test de Kolmogorov-Smirnov ait rejeté l’hypothèse nulle au seuil de 5%.
4. Les données autour du confinement
— Contexte
En cette année particulière, le confinement vient tout arrêter, ou presque. Nous avons eu l’idée de comparer les données entre avant, pendant et après le confinement. En effet, une opinion générale se dégage : « La pollution a baissé pendant le confinement ». Pour cela, nous disposons de 4 Pollubike, dont deux qui ont tourné pendant les trois différentes périodes. Nous avons donc cherché à savoir si cette idée était exacte. Par ailleurs, il semble que la pollution ait repris son cours après le confinement. Nous allons donc vérifier cette hypothèse également.
— La pollution a-t-elle diminué pendant le confinement ?
Posons quelques éléments pour nos tests : x = « PM10 avant le confinement » et y = « PM10 pendant le confinement ». Suite à des tests de corrélation, nous avons constaté que les PM25 et les PM10 sont extrêmement corrélés, les conclusions apportées sur les séries de données x et y sont donc valables avec les séries de données prenant en compte nos PM25
Nous réalisons les tests suivants :
– le test T de Student
– le test Mann-Whitney
– le test Kolmogorov-Smirnov
– et un test sur la variance
Ces graphiques nous permettent de visualiser nos séries :
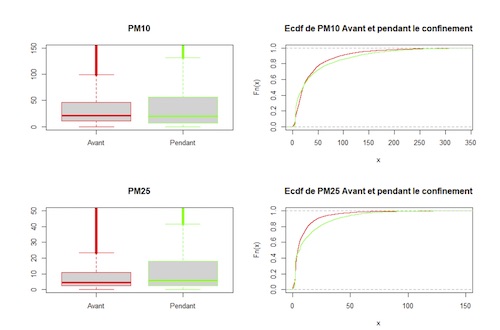
ecdf : empirical cumulative distribution function, fonction de répartition empirique.
a. Test de Student
On prend H0 : « La différence en termes de moyenne est plus faible que 0 », et comme hypothèse alternative H1 : « La différence en termes de moyenne est plus grande que 0 ». On obtient une p-valeur = 2.879e-09 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
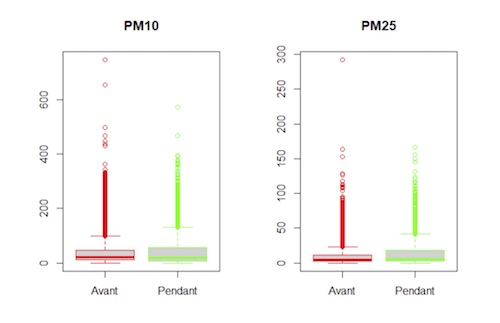
Nous pouvons néanmoins constater sur les boxplots ci-dessus que nos populations contiennent beaucoup de valeurs extrêmes. Il convient de vérifier que la conclusion du test n’est pas un artefact dû à ces valeurs extrêmes. Pour cela, nous avons composé les données avec le logarithme, ce qui a pour effet de tasser les grandes valeurs. Nous comparons donc log(x) et log(y).
On obtient p-valeur = 0.4875 > 0.05. On ne peut pas rejeter H0.
Il ne semble pas y avoir de différence significative entre les deux populations en termes de moyenne.
b. Test de Mann-Whitney
On prend H0 : « Il y a un décalage d’emplacement entre les deux populations supérieur à 0 (vers la droite) », et comme hypothèse alternative H1 : « Il n’y a pas de décalage d’emplacement entre les deux populations supérieur à 0 ». On obtient une p-valeur = 0.01579 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
Il ne semble pas y avoir de décalage. Il n’y a pas de différence significative entre avant et pendant, ce qui confirme le test T de Student des log.
c. Test de Kolmogorov-Smirnov
On effectue plusieurs tests Kolmogorov-Smirnov. On a trois hypothèses alternatives et les p-valeurs suivantes :
H1 : « La fonction de répartition de y est au-dessus de celle de x », p-valeur = 2.2e-40 < 0.05.
H1 : « La fonction de répartition de y est en dessous de celle de x », p-valeur = 1.9e-8 < 0.05.
H1 : « La fonction de répartition de y est différente de celle de x », p-valeur = 0 < 0.05.
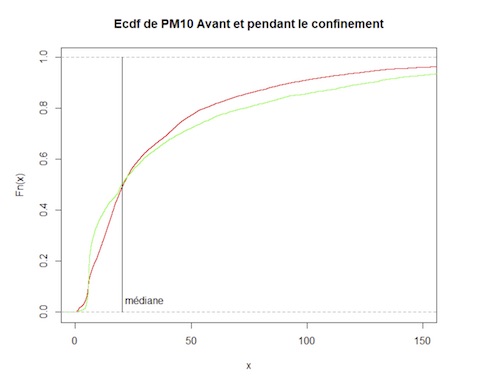
Combiné avec l’analyse des graphiques représentant les deux fonctions de répartition des PM10 avant le confinement et après le confinement, on peut conclure des tests trois informations :
Les deux fonctions des répartitions sont très significativement différentes.
La fonction de répartition de x est significativement au-dessus de y jusqu’à approximativement la médiane. La première moitié des valeurs d’avant sont significativement plus faibles que celles pendant le confinement.
La fonction de répartition de y est significativement en dessous de x à partir de la médiane. La deuxième moitié des valeurs d’avant le confinement sont significativement plus grandes que celles pendant le confinement.
d. Test sur la variance
On prend H0 : « La variance des PM10 est plus faible x : pendant que y : avant », l’hypothèse alternative étant donc H1 : « La variance des PM10 est plus grande x : pendant que y : avant ». On obtient une p-valeur = 0, on peut donc rejeter H0 et admettre H1 vraie.
Cependant, les données recueillies possèdent beaucoup de valeurs extrêmes. Pour éviter de faire des conclusions hâtives, on compose nos séries avec la fonction logarithme. On compare donc log(x) et log(y). On obtient une p-valeur = 8.9e-14 < 0.05. Le résultat reste inchangé.
Il y a une plus grande dispersion entre les valeurs pendant le confinement et celles d’avant le confinement.
e. Conclusion
À l’aide de ces différents tests, nous avons réussi à obtenir de nombreuses informations qui vont nous permettre de conclure sur si oui ou non, la pollution a baissé pendant le confinement. La réponse peut sembler surprenante car on s’attendait à ce que la pollution baisse pendant le confinement. Cela peut être expliqué par le fait que les usines de production et les espaces bureautiques (principaux lieux de pollution ) étaient fermés durant le confinement. Cependant, ce que l’on obtient, ce sont des niveaux de pollutions semblables avant et pendant le confinement. En effet, les personnes étant forcées à rester chez elles, la pollution dans les quartiers résidentiels et le centre-ville était plus élevée.
— Est-ce que la pollution a repris après le fconfinement le même niveau qu’lle avait avant ?
Posons quelques éléments pour nos tests : x = « PM10 avant le confinement », et z = « PM10 après le confinement ».
Pour étudier la question, nous allons vérifier si :
– la qualité de l’air après le confinement est la même qu’avant ;
– et si l’hypothèse précédente est fausse, la qualité de l’air après le confinement est plus grande qu’avant.
1) Avant = Après ? On compare x à z.
a) test T de Student
On prend H0 : « La différence en termes de moyenne est nulle », et comme hypothèse alternative H1 : « La différence en termes de moyenne n’est pas égale à 0 ». On obtient une p-valeur = 0.0001654 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
Après passage au logarithme on obtient une p-valeur = 5.218e-10 < 0.05, ce qui confirme que le résultat obtenu précédemment n’est pas un artefact dû aux valeurs extrêmes.
Il existe donc une différence significative entre avant et après.
b) test de Mann-Whitney
On prend H0 : « Il n’y a pas de décalage d’emplacement entre les deux populations », et comme hypothèse alternative H1 : « Il y a un décalage d’emplacement entre les deux populations non nul ». On obtient une p-valeur = 7.552e-12 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
On arrive à la même conclusion que le test T de Student au log
c) test de Kolmogorov-Smirnov
On prend H0 : « Les deux fonctions de répartition sont identiques », et comme hypothèse alternative H1 : « Les deux fonctions de répartition sont différentes ».
On obtient une p-valeur = 0 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
Les deux fonctions de répartition ne sont pas identiques, et les deux séries ne sont donc pas semblables en répartition. Même conclusion que précédemment.
d) conclusion
La qualité de l’air après le confinement n’est pas la même qu’avant ce dernier. Alors est-elle supérieure ?
2) Avant < Après ? On compare toujours x à z.
a) Test T de Student
On prend H0 : « La différence en termes de moyenne est inférieure à 0 », et comme hypothèse alternative H1 : « La différence en termes de moyenne est supérieure à 0 ». On obtient une p-valeur = 8.268e-05 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
Après passage au logarithme on obtient une p-valeur = 2.609e-10 < 0.05, ce qui confirme que le résultat obtenu précédemment n’est pas un artefact dû aux valeurs extrêmes.
b) Test de Mann-Whitney
On prend H0 : « Il y a un décalage d’emplacement entre les deux populations inférieur à 0 (vers la gauche) », et comme hypothèse alternative H1 : « Il n’y a pas de décalage d’emplacement entre les deux populations inférieur à 0 ».
On obtient une p-valeur = 3.776e-12 < 0.05. On peut donc rejeter H0 et on suppose H1 vraie.
Il y a donc une différence significative entre avant et pendant, ce qui confirme le test T de Student des log.
c) Test de Kolmogorov-Smirnov
On effectue deux tests différents :
– H1 : « La fonction de répartition de x est au dessus de z », p-valeur = 1.464325e-20 < 0.05
– H1 : « La fonction de répartition de x est en dessous de z », p-valeur = 0.9863513 > 0.05
La fonction de répartition de x est au-dessus de celle de z, et non en dessous. Alors les valeurs de pollution avant le confinement sont inférieures en distribution.
d) Conclusion
Tous les tests confirment significativement la même conclusion : les valeurs de PM10 sont significativement supérieures après le confinement, en moyenne, en moyenne des logs, en localisation, et en distribution.
III. Conclusion
Pollubike a été une grande occasion afin de se poser des questions sur l’utilisation des statistiques dans le but d’améliorer un projet scientifique. Dans notre cas, nos données nous ont permis de remarquer que l’envoi était trop aléatoire, et de prouver que l’ajout du condensateur a bien résolu ce problème. De même, nous avons pu vérifier que le sens de l’ouverture du Pollubike n’a pas d’influence sur les mesures. L’utilisation des statistiques a été très utile afin de mettre en évidence les conséquences du confinement sur la qualité de l’air dans les rues de Massy. Nous espérons désormais pouvoir mieux comprendre ce qui influence la pollution. Cela permettrait à l’urbanisme de demain de prendre en compte ces facteurs et ainsi réduire la pollution subie par les citadins.